人工智能-CS3317
Part 1 Concept
- 人工智能(AI, Artificial Intelligence) 的定义
课件 lecture1 第 4 页: 人工设计程序, 让机器可以像人一样智慧地行动
- Views of AI
Views of AI fall into four categories:
Thinking humanly / rationally
Acting humanly / rationally
The textbook advocates ==”acting rationally”==
Thinking humanly -> cognitive modeling
1960s “cognitive revolution”: informationprocessing psychology
now distinct from AI
Acting humanly -> Turing Test
目的: 设计测试以验证计算机是否真的具有智能
- ==Rational Agent 理性的智能体==:
- For each possible percept sequence, a rational agent should select an action that is expected
- to maximize its performance measure,
- given the evidence provided by the percept sequence and whatever built-in knowledge the agent has.
- An agent is ==autonomous 自主的== if its behavior is determined by ==its own experience== (with ability to learn and adapt)
e.g 下列关于 AI 的表述,正确的是:
==A. ==从长远角度来看,AI 发展的目标是让机器能够像人类一样行为,甚至比人类能做得更好
B. 智能体(agent)的自主性(autonomous)指的是按照人类设计的程序自动化地完成任务
==C. ==在图灵测试中,知识(knowledge)、推理能力(reasoning)、语言理解能力(language understanding)、学习能力(learning)是 AI系统的主要组成部分
D. 理性的智能体(rational agent)能够突破计算资源的限制,做到完美的理性化(perfect rationality )
Part 2 Searching
Problem-solving agents
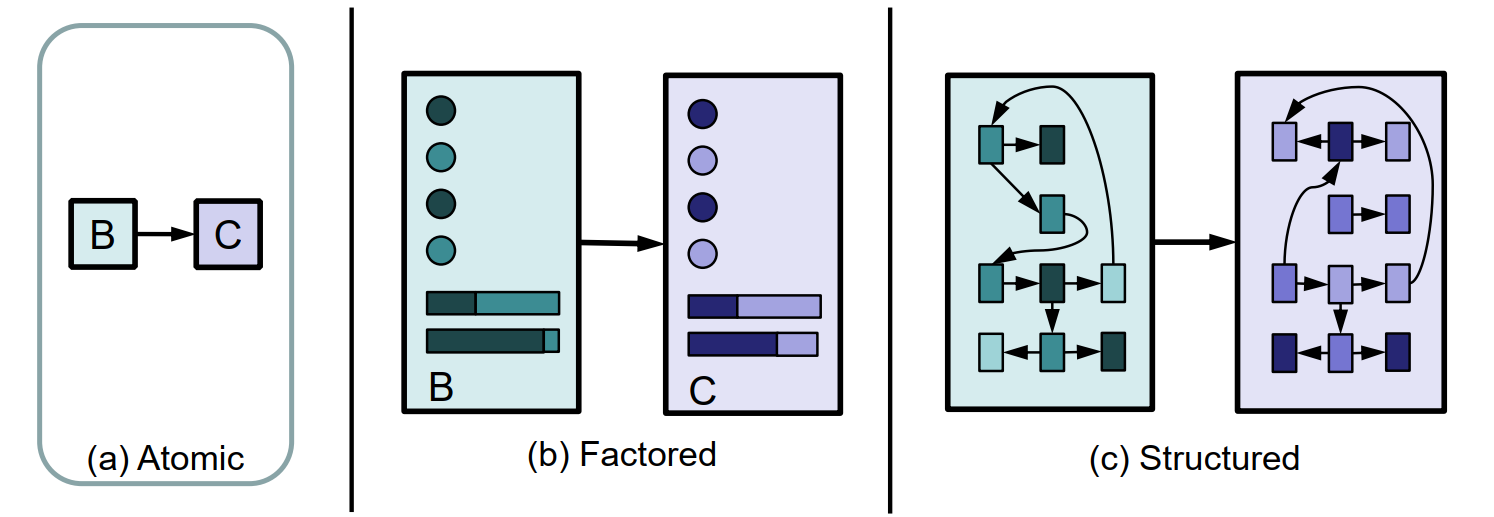
States of the world are considered as wholes, with no internal structure visible to the problem-solving algorithms
Problem formulation 建模
A problem is defined by four items:
- initial state e.g., “at Arad“
- actions or successor function S(x) = set of action–state pairs
- e.g., S(Arad) = {
, … }
- e.g., S(Arad) = {
- goal test, can be
- explicit, e.g., x = “at Bucharest”
- implicit, e.g., Checkmate(x)
- path cost (additive)
- e.g., sum of distances, number of actions executed, etc.
- c(x,a,y) is the step cost, assumed to be ≥ 0
- A solution is a sequence of actions leading from the initial state to a goal state
Uniformed search strategies 无信息搜索
https://zhuanlan.zhihu.com/p/187283548
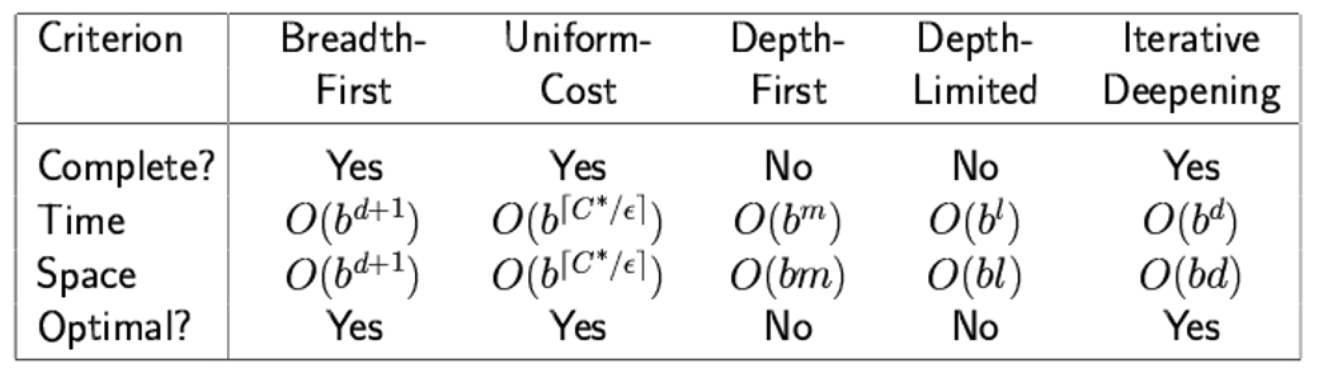
DFS和DLS找到目标节点即停止,故不符合最优性和完备性。
BFS:
- 按层次逐步扩展,遍历整个图,找到目标节点或者证明无解。
Uniform Cost Search (UCS):
- UCS仅考虑实际花费的路径代价,不使用任何启发式函数。
- 它以代价最小的顺序扩展节点,确保找到的解是代价最小的解。
- -> 使用启发式函数则发展为==A*搜索==。
DFS -> DLS -> IDS:
- DFS从起始节点开始,沿着图的深度方向尽可能深地探索。
- DLS在DFS的基础上,限制深度优先搜索的深度,防止无限深度的问题。
- IDS在DLS的基础上,不断增加深度限制来达到BFS和DFS的综合效果。
考虑使用深度受限的 DFS 算法(Depth-limited search)来搜索目标状态 S。假设目标状态 S 所在的层深度为 d,限制的搜索深度为l,那么以下说法正确的是
==A. ==如果 l>d,那么该算法是完备的(complete)
B. 如果 l<d,那么该算法是完备的
C. 如果将深度的 DFS 算法改为迭代加深算法(Iterative deepening),初始迭代深度 l<d,那么该算法是不完备的
==D. ==如果将深度的 DFS 算法改为选代加深算法,初始迭代深度如果 l<d,那么该算法是完备的
Informed search strategies 启发式搜索
Greedy best-first search 贪婪搜索
use an evaluation function f(n) for each node
→ Expand most promising paths
- Evaluation function
- f(n) = h(n) = estimate of cost from n to goal (heuristic)
不符合最优性和完备性。
A* search
- Evaluation function
- Avoid Expanding Expensive Pathes
- f(n) = g(n) + h(n)
- g(n) = cost so far to reach n
- f(n) = estimated total cost of path through n to goal
Heuristic function
Admissible
An admissible heuristic never ==overestimates== the cost to reach the goal:
$h(n) \le h^(n)$ ($h^(n)$ 为真实开销)
e.g 对于当前问题而言,如果f与g都是满足可接受性(admissible)的启发函数(heuristics),那么以下函数中,哪些选项也一定满足可接受性?
==A. max (f, g) ==
==B. min (f, g) ==
C. (fg)^0.5 + 1
==D. (fg)^0.5 - 1==
Consistent
A heuristic is consistent if for every node n, every successor n’
of n generated by any action a, then $h(n) \le c(n,a,n’)+h(n’)$
$f(n)$ is non-decreasing along any path.
对于 A* 算法,如果启发式函数 h(n) 满足一致性(也称为“单调性”或“单调递增性”),那么在搜索树中的每条路径上,子节点的 f 值不会小于其父节点的 f 值。
Local search algorithms 局部搜索
interested in the solution state but not in the path to that goal
关注当前状态及其邻近状态,而不是系统性地探索整个搜索空间。
2 key advantages:
- use very little memory
- find reasonable solutions in large or infinite (continuous) state spaces.
爬山法 Hill-Climbing
过程:
- 初始状态: 选择一个初始状态。
- 邻近状态: 根据问题的操作或移动规则,找到当前状态的邻近状态。
- 评估: 评估邻近状态的质量。
- 移动: 移动到具有更好评估的邻近状态。
- 迭代: 重复上述步骤直到达到局部最优解或无法移动。
问题:
- 局部最优解: 爬山法可能会陷入局部最优解而无法找到全局最优解。
- 平原问题: 如果在当前状态的所有邻近状态中都没有更好的解,算法可能会停滞在平原。
模拟退火 Simulated annealing
“退火”的目的: 模拟退火算法是对爬山法的改良,其目的是通过引入一定的随机性来跳出局部最优解,以更有可能找到全局最优解。
过程:
- 初始温度: 设定初始温度,表示算法接受较差解的概率。
- 邻近状态: 根据问题的操作或移动规则,找到当前状态的邻近状态successor。
- 评估: 评估邻近状态的质量。
- 移动: 移动到邻近状态,即使质量较差,以一定概率接受较差解。
- 温度下降: 通过降低温度,逐渐降低接受较差解的概率。
- 迭代: 重复上述步骤直到达到一定条件(如温度足够低)。
选择“坏”移动的概率与哪些因素有关:
- 温度: 初始时,温度较高,接受较差解的概率较大,随着迭代过程温度逐渐降低,接受较差解的概率减小。
遗传算法 Genetic algorithms
定义: 遗传算法是一种基于生物遗传学原理的优化算法,通过模拟自然选择、交叉和变异的过程来搜索问题的解空间。
步骤和目的:
- 初始化种群: 随机生成初始种群,每个个体表示一个可能的解。
- 选择 Selection: 根据个体的适应度,选择一部分个体作为父代。
- 交叉 Crossover: 对选定的父代进行交叉操作,生成子代。
- 变异 Mutation: 对子代进行变异操作,引入一定程度的随机性。
- 评估: 评估种群中每个个体的适应度。
- 进化: 重复选择、交叉、变异步骤,直到满足停止条件(达到最大迭代次数或找到满意解)。
通过模拟进化过程,希望通过适应度高的个体在种群中传递有利的特征,逐渐优化整个种群,以找到问题的解。
e.g 关于遗传算法 (genetic algorithm),下列说法正确的有:
A. 遗传算法属于一种局部搜索 (local search) 算法
==B. ==当选代次数达到预设的上界或种群 (population)的适应度(fitness) 达到期望值后,可以结束遗传算法
==C. ==在算法中,我们会根据个体的适应度选择产生子集,然后用子集中的个体产生”后代(offspring)
==D. ==交叉(crossover)的目的是产生”后代”,进行搜索状态的转移
对抗搜索
Iterative Definition:
Each player should choose the best action leading to the highest utility for it assuming both players will choose the best actions afterwards.
https://www.bilibili.com/video/BV1v94y1r7F8
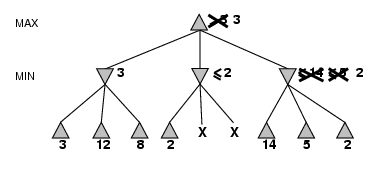
1. MiniMax 算法
Two player : MAX and MIN
Task : find a “best” move for MAX
Assume that MAX moves first, and that the two players
move alternately.
- MAX node
- nodes at even-numbered depths correspond to positions in which it is MAX’s move next
- MIN node
- nodes at odd-numbered depths correspond to positions in which it is MIN’s move next

- nodes at odd-numbered depths correspond to positions in which it is MIN’s move next
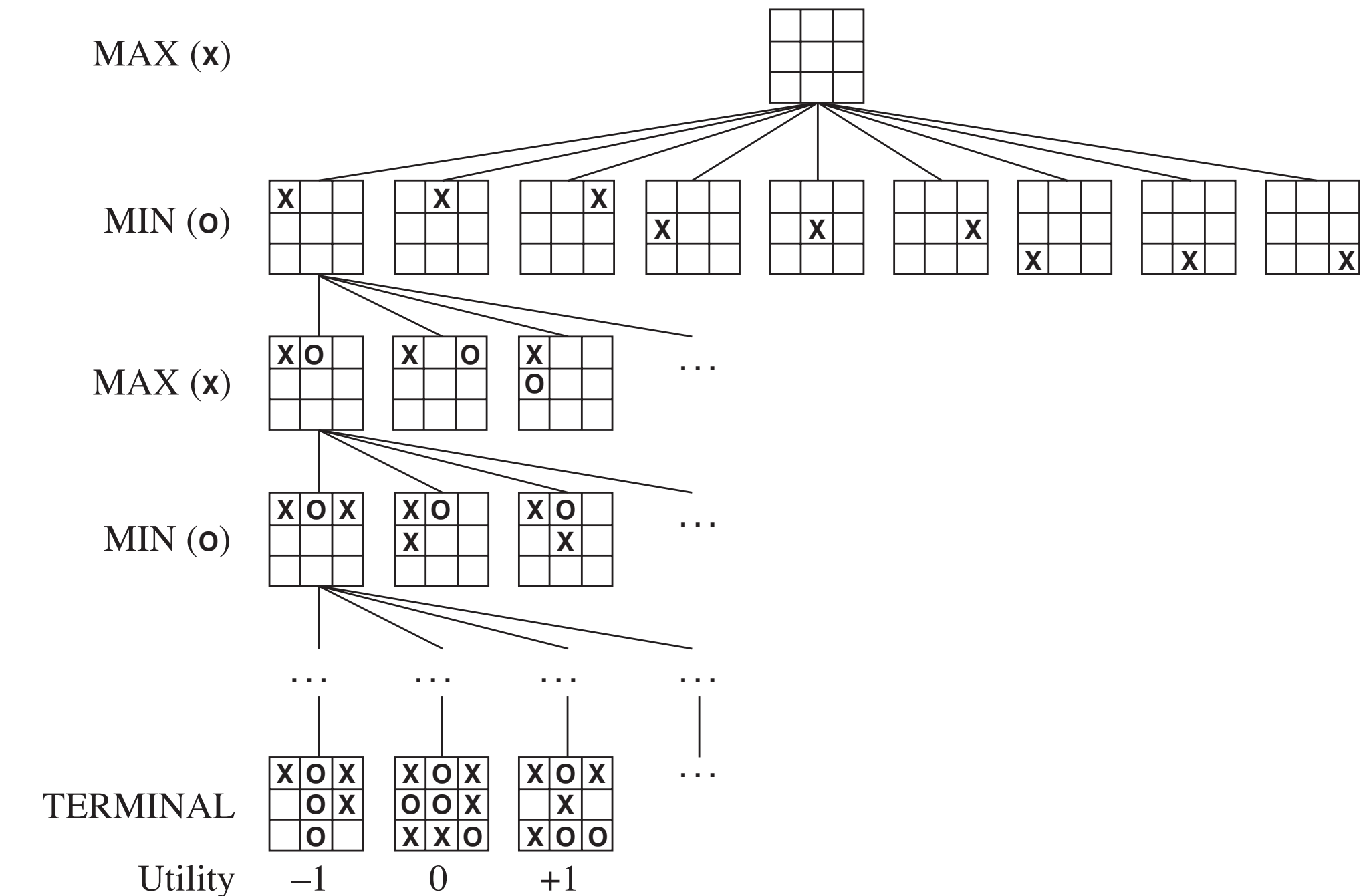
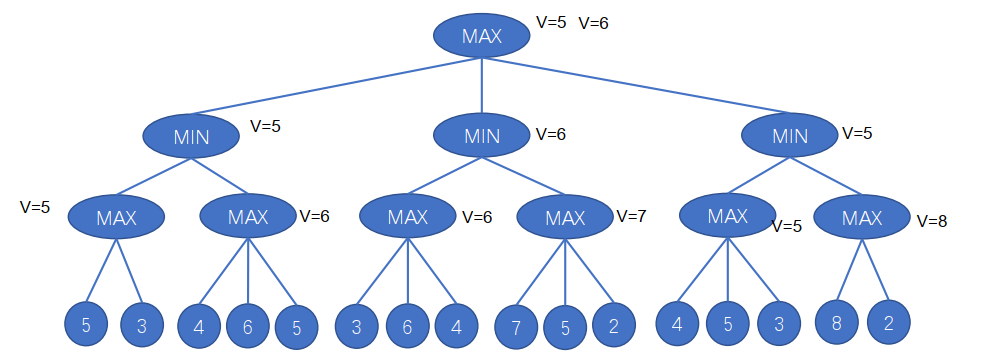
流程:
- 建立决策树: 从当前局面开始,建立一棵完整的对抗搜索树,其中每个节点表示一个游戏状态,每个边表示一步合法的移动。
- 评估叶节点: 对于树中的叶节点,使用评估函数(evaluation function)进行评估,得到一个估值,表示该节点的局面对于当前玩家的好坏程度。
- 递归传递值: 从树的底部开始,逐层向上递归传递估值,玩家轮流选择最大或最小值,以反映对手的最佳选择和己方的最佳应对。
- 最终决策: 在根节点选择具有最高估值的动作,作为最终的决策。
Keypoints:
- 最佳动作假设: Mini-Max算法假设每个玩家都会选择使其得分最大化(最佳动作)或最小化(对手最佳动作)的动作。
- 复杂性处理: 对于Mini-max树规模太大的问题,可以通过深度上和宽度上的简化来处理。-> DLS和Alpha-beta剪枝
Properties
- Complete? Yes (if tree is finite)
- Optimal? Yes (against an optimal opponent)
- Time complexity? O(bm) (b-legal moves; m- max tree depth)
- Space complexity? O(bm) (depth-first exploration)
2. 深度上的简化:Depth-limited search
For many problems, you do not need a full contingent plan at the very beginning of the game.
关键点: Depth-limited search是对MiniMax的深度上的简化,即限制搜索的深度。对于未探索到的叶节点,需要定义一个evaluation function来估计局面好坏。
Evaluation function
- should order the terminal states in the same way as the true utility function;
- the computation must not take too long!
- for nonterminal states, the evaluation function should be strongly correlated with the actual chances of winning.
Eg. Tic-tac-toe
If p is not a winning for either player, e(p) = (no. of complete rows, columns, or diagonals that are still open for MAX) - (no. of complete rows, columns, or diagonals that are still open for MIN)
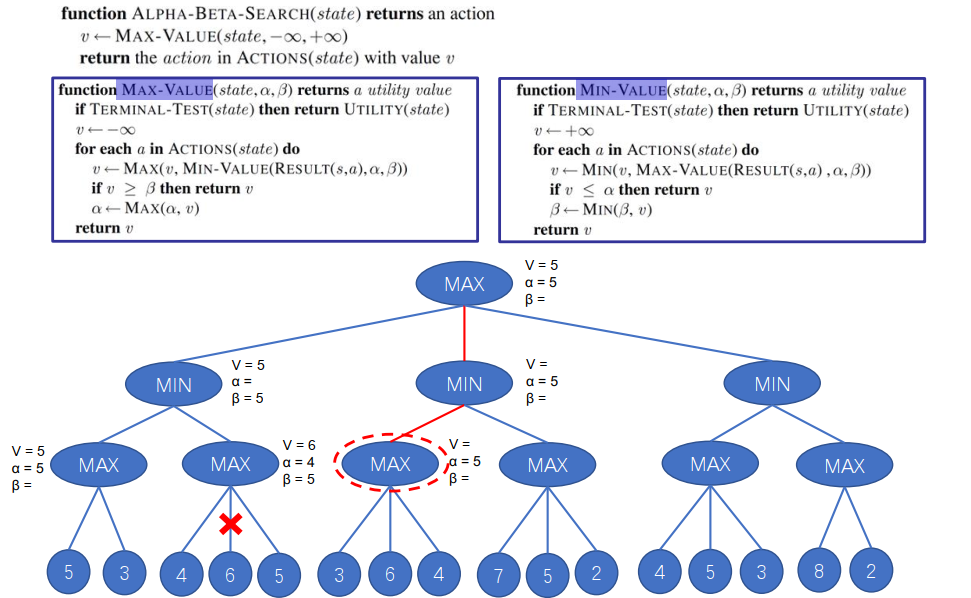
3. 宽度上的简化:Alpha-beta 剪枝
Compute the correct decision without looking at every node (consider the bounds of the minimax value)
Alpha和Beta的作用:
- Alpha: 用于保存当前节点的最大值。
- Beta: 用于保存当前节点的最小值。
比较节点与 alpha、beta 值的关系:
- 节点值大于等于 beta: 剪枝,因为对手不会选择这个节点,它已经不会影响当前节点的值。
- 节点值小于等于 alpha: 剪枝,因为当前玩家不会选择这个节点,它已经不会影响当前节点的值。
节点值介于 alpha 和 beta 之间: 更新 alpha 或 beta 的值。
在Max层,alpha是一个下界;在Min层,beta是一个上界。
Key points
- The MAX player will only update the value of α.
- The MIN player will only update the value of β.
- While backtracking the tree, the node values will be passed to upper nodes instead of values of α and β.
- Only pass the α, β values to the child nodes.
Properties
- Pruning does not affect the final result
- Effectiveness depends on the ordering of successors
- With “perfect ordering,” time complexity = O(bm/2)
→ doubles depth of searchCSP问题
Standard search formulation (incremental)
States are defined by the values assigned so far
- Initial state: the empty assignment { }
- Successor function: assign a value to an unassigned variable that does not conflict with current assignment
→ fail if no legal assignments - Goal test: the current assignment is complete
- This is the same for all CSPs
- Every solution appears at depth n with n variables
→ use depth-first search - Path is irrelevant, so can also use complete-state formulation
- $b = (n - l )d$ at depth $l$, hence $n! ·d^n$ leaves
Backtracking search
- DFS for CSPs with single-variable assignments
- the basic uninformed algorithm for CSPs
Only need to consider assignments to a single variable at each node ( b = d )
There are $n! ·d^n$ leaves, $d^n$ possible complete assignments.Backtracking search = DFS + two improvements
- Idea 1: One variable at a time
Variable assignments are commutative
Only need to consider assign value to a single variable at each step\[WA = red then NT = green] same as \[NT = green then WA = red] - Idea 2: Check constraints as you go
Consider only values which do not conflict previous assignments
May need some computation to check the constraints “Incremental goal test”
Which variable should be assigned next?
- Most constrained variable:
- choose the variable with the fewest legal values
- a.k.a. minimum remaining values (MRV) heuristic
- choose the variable with the fewest legal values
- Most constraining variable (Tie-breaker):
- choose the variable with the most constraints on remaining variables
- the degree heuristic
- choose the variable with the most constraints on remaining variables
- Given a variable, choose the least constraining value:
- The one that rules out the fewest values in the remaining variables
首先选择 most constrained variable, minimum remaining values,如有多个这样的变量,再根据 most constraining variable
Forward checking 前向检查
- Idea:
- Keep track of remaining legal values for unassigned variables
- Terminate search when any variable has no legal values
- Limitation:
- Arc consistency 弧一致性(弧相容性)
- X →Y is consistent iff for every value x of X there is some allowed y
- Arc consistency 弧一致性(弧相容性)
- The problem:
- It makes the current variable arc-consistent, but doesn’t look ahead and make all the other variables arc-consistent
e.g 在一个 CSP 问题中,我们需要满足的要求为 $x+3>y$,其中x 属于 $x\in{0,1,3}$,而$y\in{3,4,5}$,那么以下关于弧相容性(arc consistency)的说法中,正确的是:
A.弧x->y与弧y->x满足弧相容性
B.弧x->y与弧y->x都不满足弧相容性
C.弧x->y满足弧相容性,但弧y->x不满足弧相容性
==D.弧y->x满足弧相容性,但弧x->y不满足弧相容性==
Arc-3
一种用于处理约束满足问题的算法,它的目标是通过维护弧一致性(arc-consistency)来降低搜索空间。AC-3是一种全局的推理算法,与前向检测相比,它更注重全局的一致性。
算法步骤:
- 初始化队列: 将所有约束的弧添加到一个队列中。
- 循环处理队列:
- 从队列中取出一个约束弧(arc)。
- 对于弧起点的变量的每个可能取值,检查是否存在与该值冲突的其他值。如果存在冲突,则将该值==从弧起点的定义域中移除==。
- 如果某个变量的定义域发生变化,将==邻居变量指向该变量的约束弧==添加到队列中,进一步迭代邻居变量的约束弧的定义域。
- 判定一致性:
- 如果某个变量的定义域为空,表示出现了不一致,算法中止,进行回溯。
- 如果所有变量的定义域都不为空,表示系统是一致的,可以继续进行搜索。
AC-3的优势和特点:
- 全局一致性: AC-3通过在整个问题的约束图上进行推理,更全局地维护弧一致性,有助于减小搜索空间。
- 提前检测不一致性: 与前向检测不同,AC-3在推理的过程中能够更早地检测到不一致性,因为它考虑了整个约束网络的信息。
- 减少搜索空间: 通过及时地削减变量的定义域,AC-3有助于在搜索之前减小问题的规模,提高解决问题的效率。
- 适用于约束满足问题: AC-3主要用于处理约束满足问题,其中变量之间存在约束关系。
Part3 Logical Agent
Propositional Logic Models
Logic in general
- ==Logics== are formal languages for representing information such that conclusions can be drawn
- ==Syntax 语法== defines the sentences in the language
- ==Semantics 语义== define the “meaning” of sentences;
- i.e., define truth of a sentence in a world
- E.g., the language of arithmetic
Entailment
Entailment means that one thing follows from another: $KB \models A$
Entailment is a relationship between sentences (i.e., syntax) that is based on semantics.
Inference: Proofs
- A proof is a demonstration of entailment between $\alpha$ and $\beta$
- Method 1: model-checking
- For every possible world, if $\alpha$ is true make sure that is $\beta$ true too
- OK for propositional logic (finitely many worlds); not easy for first-order logic
- Method 2: theorem-proving
- Search for a sequence of proof steps (applications of inference rules) leading from $\alpha$ to $\beta$
- E.g., from $P \wedge (P \Rightarrow Q)$, infer Q by Modus Ponens
Properties
- Sound algorithm: everything it claims to prove is in fact entailed
- Complete algorithm: every sentence that is entailed can be proved
Uncertainty
Probability
先验概率(Prior Probability):
先验概率是在考虑任何新证据或信息之前,对事件的概率进行的初始估计。它基于以往的知识、经验或主观判断。数学上表示为P(A),其中A是事件。
条件概率(Conditional Probability):
条件概率是指在给定另一个事件发生的条件下,某一事件发生的概率。表示为P(A|B),读作“A在给定B的条件下发生的概率”,其中A和B是两个事件。
条件概率可以通过以下公式计算:
$P(A|B) = \frac{P(A \cap B)}{P(B)}$
后验概率(Posterior Probability):
后验概率是在考虑了新的观测数据或证据之后,对事件的概率进行重新估计。它是先验概率与新观测数据相结合得出的概率。在贝叶斯统计学中,后验概率是通过使用贝叶斯定理计算得到的。
$P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)}$
其中:
- $P(A|B)$ 是后验概率,表示在观测到B的情况下A的概率。
- $P(B|A)$ 是条件概率,表示在A的情况下观测到B的概率。
- $P(A)$ 是先验概率,表示在没有新观测数据的情况下A的概率。
- $P(B)$ 是用于归一化的边际概率,表示B的概率。
e.g 有C1和C2两个城市,它们的人口比例为 1:3。根据今年疾病发生率的统计结果,C1城 市污染严重,居民患癌症的比率为 0.1%,而 C2 城市的居民患癌症的比率为 0.02%。现在医院接诊了一名癌症患者,该患者来自 C1 市的率为?
62.5%
联合概率(Joint Probability):
联合概率是指两个或多个事件同时发生的概率。假设有两个事件A和B,它们的联合概率表示为P(A and B),表示同时发生A和B的概率。联合概率的计算通常使用乘法规则:
$P(A \cap B) = P(A) \cdot P(B|A)$
其中,$P(B|A)$表示在事件A发生的条件下,事件B发生的条件概率。
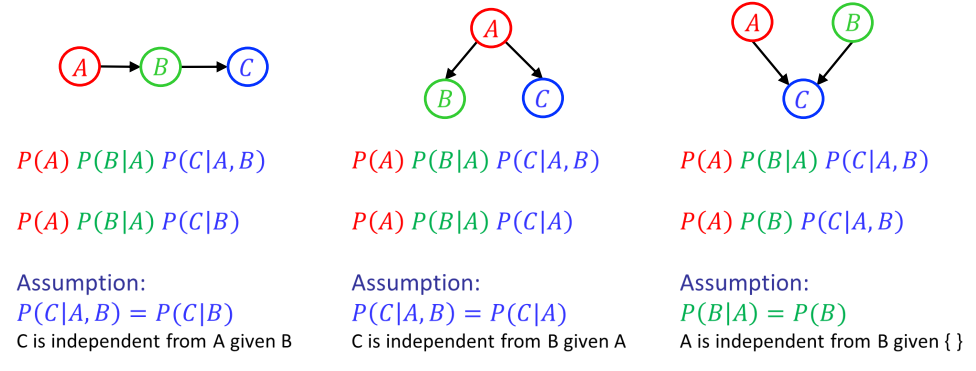
条件独立定义(Conditional Independence):
两个事件A和B在给定另一个事件C的条件下是独立的,如果满足以下条件:
$P(A \cap B | C) = P(A | C) \cdot P(B | C)$
这表示在给定事件C的情况下,事件A和事件B的联合概率等于它们各自的条件概率的乘积。如果这个等式成立,我们称A和B在给定C的条件下是条件独立的。
朴素贝叶斯 Naive Bayes
朴素贝叶斯是一种基于贝叶斯定理的分类算法。它的”朴素”体现在对于特征之间的条件独立性的假设,即在给定类别的条件下,每个特征都是相互独立的。这个假设是朴素贝叶斯算法的核心,使得计算条件概率变得简化。
$P(\text{Cause},\text{Effect}1, … ,\text{Effect}_n) = P(Cause) \prod{i}^{ }P(\text{Effect}_i|Cause)$
朴素贝叶斯分类过程:
- 建立模型: 基于训练数据,计算各个类别的先验概率 $P(C_i)$ 和每个特征在各个类别下的条件概率 $P(X_j | C_i)$。
- 输入测试数据: 对于给定的测试数据,计算它属于每个类别的后验概率。
- 选择类别: 选择具有最高后验概率的类别作为最终的分类结果。
Probabilistic Reasoning
Bayesian networks
贝叶斯网络(Bayesian Network),也称为信念网络(Belief Network)或概率图模型,是一种用于表示变量之间条件依赖关系的图结构。它使用有向无环图(DAG)来表示变量之间的依赖关系,其中节点表示随机变量,边表示变量之间的依赖关系。
具体来说,贝叶斯网络包含两个主要组成部分:
- 节点(Nodes): 节点表示随机变量,每个节点代表一个特定的事件或状态。
- 边(Edges): 有向边表示变量之间的条件依赖关系。如果节点A有一条指向节点B的边,就表示在给定节点A的情况下,节点B发生的概率可能会受到影响。
每个节点都有一个条件概率表(Conditional Probability Table,CPT),描述了该节点在给定其父节点的条件下的概率分布。
因子分解定理(Node Given Its Parents):
在贝叶斯网络中,因子分解定理是指一个节点在给定其父节点的条件下,可以被分解为一个条件概率表的乘积。这定理表达了节点和其父节点之间的联合概率分布的关系。
对于一个节点X和其父节点集合Pa(X),有:
$P(X, Pa(X)) = P(X | Pa(X)) \cdot P(Pa(X))$
其中:
- $P(X, Pa(X))$ 表示节点X和其父节点集合Pa(X)的联合概率分布。
- $P(X | Pa(X))$ 表示节点X在给定其父节点集合Pa(X)的条件下的概率分布。
- $P(Pa(X))$ 表示父节点集合Pa(X)的概率分布。
这个因子分解定理允许贝叶斯网络中的联合概率分布可以通过对每个节点的条件概率表进行分解和组合来计算,使得网络的表示更为紧凑且易于处理。
Conditional Independence
Bayesian Sampling
HW3. Prob2
用于从贝叶斯网络中抽样的方法。
先验采样(Prior Sampling)
过程:
- 从网络的先验概率分布中对每个节点进行采样,得到一个样本。
概率计算:
- 根据每个节点的先验概率表进行采样。
拒绝采样(Rejection Sampling)
过程:
- 对每个节点进行先验采样。
- 根据观测数据,决定是否接受该样本。
拒绝操作:
- 如果样本不符合观测数据,拒绝该样本。
似然采样(Likelihood Weighting)
过程:
- 对观测变量赋值。
- 从网络的条件概率分布中对每个非观测节点进行采样,同时计算权重。
- 根据观测数据的似然性对样本进行加权。
概率计算:
- 对非观测节点按照条件概率表进行采样,同时计算相应的权重。
- 权重计算:$w = w \times P(\text | \text)$
吉布斯采样(Gibbs Sampling)
过程:
- 初始化所有节点的值。
- 随机选择一个节点,根据其条件概率表采样新值。
- 重复步骤2,直到达到收敛条件。
何时采样:
- 在每次迭代中,只采样一个节点,而不是整个样本。
证据变量处理:
- 如果节点是观测节点,则保持其值不变。
采样哪些节点:
- 在每次迭代中,只采样一个节点,其他节点保持不变。
条件概率计算:
- 对于每个节点,根据其条件概率表和当前其他节点的值计算条件概率。
贝叶斯采样方法根据具体的网络结构和需要的样本,选择适合的方法。各种方法的选择会受到计算效率和样本质量的影响。
Markov blanket
在概率图模型中,马尔可夫毯 Markov Blanket 是一个节点的最小邻居集,给定其马尔可夫毯的信息,该节点与其他所有节点条件独立。
换句话说,马尔可夫毯是一组节点,这组节点的信息足以使给定节点在图中的其他节点的信息条件下变得独立。
马尔可夫毯的定义:
对于一个图模型中的节点X,其马尔可夫毯定义为==所有与X有边连接的节点,以及所有与X的邻居节点相邻的节点==。形式化地表示,节点X的马尔可夫毯记为 $\text{MB}(X)$,满足:
$\text{MB}(X) = \text{Pa}(X) \cup \text{Children}(X) \cup \text{Pa}(\text{Children}(X)) \setminus {X}$
马尔可夫毯包含以下节点:
- 节点X的父节点($\text{Pa}(X)$)。(父亲)
- 节点X的子节点($\text{Children}(X)$)。(儿子)
- 节点X的所有子节点的父节点($\text{Pa}(\text{Children}(X))$)。(配偶)
- 上述节点集合中去掉节点X本身($\setminus {X}$)。
马尔可夫毯的概念对于贝叶斯网络和马尔可夫网络等概率图模型的推断过程非常重要,因为它提供了一种局部结构,通过它,我们可以捕捉到一个节点在给定其马尔可夫毯的条件下的独立性。
Probabilistic Reasoning over Time
Hidden Markov Model (HMM)
马尔贝夫链
状态空间 States Space
无记忆性 Memorylessness
- 转移矩阵 Transition Matrix
->
- 稳态分布 Stable Distribution
- 遍历性 -> 唯一稳态
- 常返性 recurrent
- 存在返回路径
- 非周期性
- 两两连通
- 常返性 recurrent
- 遍历性 -> 唯一稳态
HMM建模(Hidden Markov Model)
HMM是一种用于建模时序数据的概率图模型。它包含两个主要组成部分:隐状态序列和观测序列。
- 隐状态序列(Hidden States): 表示系统内部不可见的状态。在每个时刻,系统处于一个隐状态,但我们无法直接观测到它。
观测序列(Observations): 表示在每个时刻我们可以直接观测到的数据。
状态转移概率(Transition Probabilities):
- $p(yt|y{t-1})$
- 描述在不同时刻隐状态之间的转移概率。
- 发射概率(Emission Probabilities):
- $p(x_t|y_t)$
- 描述在每个时刻从隐状态到观测状态的概率。
- 初始概率分布(Initial Probabilities):
- $p(y_1)$
- 描述在第一个时刻系统处于每个隐状态的概率。
2. 评价 HMM 中某个序列出现的概率:前向、后向算法:
前向算法(Forward Algorithm):
用于计算给定观测序列的概率。通过动态规划,从序列的开始到当前时刻,逐步计算到达当前状态的所有路径的概率之和。
后向算法(Backward Algorithm):
与前向算法相反,从序列的结束到当前时刻,逐步计算从当前状态到达序列末尾的所有路径的概率之和。
前向算法和后向算法的综合结果可以用于计算给定观测序列的整体概率,即联合概率 $P(Observations | Model)$。
维特比算法 Viterbi Algorithm
用于解码给定观测序列对应的最可能的隐状态序列。
该算法利用动态规划,计算每个时刻的最可能的状态路径,最终找到使得整体概率最大的隐状态序列。
维特比算法的基本步骤包括初始化、递推、终结。通过在每个时刻选择最大概率的状态路径,算法找到整体观测序列对应的最可能的隐状态序列。
Part4 Machine learning
Basic Knowledge
Classification
无监督学习(Unsupervised Learning)
在无监督学习中,模型从==未标记==的数据中学习模式和结构。主要任务包括聚类(Clustering)和降维(Dimensionality Reduction)。
在聚类中,模型试图将数据分为具有相似特征的组,而在降维中,模型试图减少数据的特征维度。
有监督学习(Supervised Learning)
在有监督学习中,模型从标记的训练数据中学习,其中每个样本都有一个对应的标签或输出。主要任务包括分类(Classification)和回归(Regression)。在分类中,模型试图预测样本属于哪个类别,而在回归中,模型试图预测一个连续的数值。
强化学习(Reinforcement Learning)
在强化学习中,模型(代理)通过与环境的交互学习,以获得最大的累积奖励。模型通过尝试不同的行动来学习最佳策略,而环境则通过奖励或惩罚来提供反馈。
过拟合、欠拟合
过拟合(Overfitting)
过拟合指模型在训练集上表现良好,但在未见过的新数据上表现差。过拟合通常是因为模型过于复杂,过分适应训练数据中的噪声和细节。
欠拟合(Underfitting)
欠拟合指模型无法在训练集上学到足够的模式,导致在训练集和测试集上都表现不佳。通常是因为模型过于简单,不能很好地捕捉数据中的复杂关系。
分类和回归
分类(Classification)Discrete label
一种有监督学习任务,其中模型预测输入数据属于预定义的类别中的哪一个。==输出是离散的==,通常表示类别标签。例如,垃圾邮件过滤是一个二分类问题,其中类别可以是”垃圾邮件”或”非垃圾邮件”。
回归(Regression)Continuous label
一种有监督学习任务,==输出是连续的数值==。模型预测的是输入数据的数值或标签。例如,房价预测是一个回归问题,其中模型预测的是房屋的价格,这是一个连续的数值。
Linear Model
线性回归
$f_{w,b}(x)=\sum_iw_ix_i+b$
代价函数
通常采用均方误差(Mean Squared Error,MSE)来衡量预测值与真实值之间的差异。代价函数 $J(\theta)$ 的定义如下:
$J(\theta) = \frac{1}{2m} \sum{i=1}^{m} (h\theta(x^{(i)}) - y^{(i)})^2$
其中:
- $m$ 是训练样本数量。
- $h_\theta(x^{(i)})$ 是模型对第 $i$ 个样本的预测值。
- $y^{(i)}$ 是第 $i$ 个样本的真实值。
- $\theta$ 是模型的参数向量。
求解方式
直接法 Normal Equation
通过解正规方程(Normal Equation)来直接求解最小化代价函数的参数 $\theta$。正规方程的解为:
$\theta = (X^T X)^{-1} X^T y$
其中,$X$ 是包含所有样本特征的矩阵,$y$ 是包含所有样本真实值的向量。
梯度下降法
通过梯度下降法迭代地更新参数 $\theta$,使代价函数 $J(\theta)$ 达到最小值。梯度下降法的更新规则为:
$\theta_j := \theta_j - \alpha \frac{\partial}{\partial \theta_j} J(\theta)$
其中,$\alpha$ 是学习率,$\frac{\partial}{\partial \theta_j} J(\theta)$ 是代价函数对参数 $\theta_j$ 的偏导数。
正则化 Regularization
正则化:防止过拟合的技术。通常通过在损失函数中添加一个正则化项来实现。
L1 正则化(Lasso)
- 目标:最小化代价函数的同时,加上 $\lambda$ 乘以参数向量 $\theta$ 的绝对值之和。
- 代价函数:$J(\theta) = \text{MSE}(\theta) + \lambda \sum_{i=1}^{n} |\theta_i|$
- 其中,$\theta$ 是模型的参数,$\text{MSE}(\theta)$ 是均方误差损失,$\lambda$ 是正则化强度。
- 适合用于==稀疏特征选择==,可以精确地将某些特征的权重缩减至零。
L2 正则化(Ridge Regression)
- 目标:最小化代价函数的同时,加上 $\lambda$ 乘以参数向量 $\theta$ 的平方和。
- 代价函数:$J(\theta) = \text{MSE}(\theta) + \lambda \sum_{i=1}^{n} \theta_i^2$
- 其中,$\theta$ 是模型的参数,$\text{MSE}(\theta)$ 是均方误差损失,$\lambda$ 是正则化强度。
- 使所有参数都变得较小,但不精确地等于零,对所有特征的权重进行==平滑处理==,从而防止某些参数对模型的影响过大。
正则化的作用
- 防止过度拟合: 正则化通过限制模型的复杂度,减少模型对训练数据的过度拟合,提高在未见过的数据上的泛化能力。
- 特征选择: L1 正则化的效果是使得一些特征的权重精确地等于零,因此可以用于特征选择,排除对模型贡献较小的特征。
- 稳定模型: 使模型的参数更加稳定,减少参数值的大幅波动,有助于提高模型的鲁棒性。
Logistic Regression 逻辑回归
$f_{w,b}(x)=\sigma(\sum_iw_ix_i+b)$
$\sigma(z) = \frac{1}{1 + e^{-z}}$
Modeling
Logistic Regression对输入特征进行加权线性组合,然后使用Logistic函数对结果进行概率映射。它建模的是样本属于正类别的后验概率 $P(y=1 | x;\theta)$。
Logistic Regression是一种用于二分类问题的线性分类模型。通过使用Logistic函数(也称为Sigmoid函数)将线性组合的结果映射到一个[0, 1]的范围(在线性回归后加了一个sigmoid函数),表示样本属于正类别的概率,将==线性回归==变成一个==0~1输出==的分类问题。
求解方法 MLE
通过最大似然估计(Maximum Likelihood Estimation,MLE)来求解模型的参数 $\theta$。
对于二分类问题,Logistic Regression的似然函数为:
$L(\theta) = \prod_{i=1}^{m} P(y^{(i)} | x^{(i)};\theta)^{y^{(i)}} \cdot (1 - P(y^{(i)} | x^{(i)};\theta))^{1 - y^{(i)}}$
其中 $P(y | x;\theta)$ 是通过Logistic函数计算的样本属于正类别的概率。最大化似然函数等价于最小化其负对数似然(Negative Log-Likelihood):
$J(\theta) = -\frac{1}{m} \sum_{i=1}^{m} [y^{(i)} \log(P(y^{(i)} | x^{(i)};\theta)) + (1 - y^{(i)}) \log(1 - P(y^{(i)} | x^{(i)};\theta))]$
其中 $P(y | x;\theta)$ 为 Logistic 函数。
求解方法通常使用梯度下降法。
$g(z) = \frac{1}{1 + e^{-z}}$ 的导数为 $g’(z) = g(z)(1 - g(z))$。
Bayesian Learning
MLE 和 MAP 在估计参数时的区别
最大似然估计(Maximum Likelihood Estimation, MLE)
- Target: Choose 𝜃 that maximizes the probability of observed data
- Estimation:
- $\hat{\theta}{MLE} = \arg \max{\theta} P(D|\theta) = \arg \max_{\theta} \theta^{\alpha_H}(1-\theta)^{\alpha_T}$。
- Solution: 最大化似然函数
- 特点:
- As n → infinity, prior is “forgotten” ; But, for small sample size, prior is important!
最大后验估计(Maximum A Posterior Estimation, MAP)
- Target: Choose 𝜃 that maximizes the probability of given observed data and prior belief
- Estimation:
- $\hat{\theta}{MAP} = \arg \max{\theta} P(\theta|D) = \arg \max_{\theta}\frac{P(D|\theta) \cdot P(\theta)}{P(D)}$
- Solution: 最大化后验概率。
Bayes Optimal Classifier
Bayes 分类器基于贝叶斯定理,通过计算给定观测数据的后验概率来进行分类。对于两个类别 $C_1$ 和 $C_2$,给定观测数据 $X$,贝叶斯分类器选择具有最大后验概率的类别:
$P(C_i | X) = \frac{P(X | C_i) \cdot P(C_i)}{P(X)}$
其中,$P(X)$ 是一个常量,对于分类决策没有影响,因此可以简化为:
$P(C_i | X) \propto P(X | C_i) \cdot P(C_i)$
Bayes 分类器选择具有最大后验概率的类别,即:
$\hat{y} = \arg \max_{i} P(C_i | X)$
对比
1)线性回归要求变量服从==正态分布==,逻辑回归对变量分布没有要求。
2)线性回归要求因变量是==连续性数值变量==,逻辑回归要求因变量是==分类型变量==。
3)线性回归要求自变量和因变量呈==线性关系==,逻辑回归不要求自变量和因变量呈线性关系
4)逻辑回归是分析因变量==取某个值的概率与自变量==的关系,而线性回归是==直接分析因变量与自变量==的关系
朴素贝叶斯分类器,条件独立性假设
朴素贝叶斯分类器
朴素贝叶斯分类器是一种基于贝叶斯定理的分类算法,假设特征在给定类别的条件下是独立的。这是一个强假设,通常被称为条件独立性假设。
Optimal predictor (Bayes classifier) : $f^*=\arg\min_{f}P(f(x)\neq Y)$
Equivalently,
$f^{*}(x)=\arg \max _{Y=y} P(Y=y \mid X=x)$
条件独立性假设
假设特征 $X_1, X_2, \ldots, X_n$ 在给定类别 $C$ 的条件下是独立的,即:
$P(X_1, X_2, \ldots, X_n | C) = P(X_1 | C) \cdot P(X_2 | C) \cdot \ldots \cdot P(X_n | C)$
这使得朴素贝叶斯分类器的计算变得简单,因为可以通过计算每个特征在给定类别下的概率来估计整个观测数据的后验概率。
生成模型与判别模型的区别
生成模型
生成模型试图对数据的生成过程进行建模,即学习类别的联合概率分布 $P(X, Y)$。生成模型可以通过学习类别的条件概率分布 $P(X | Y)$ 和先验概率分布 $P(Y)$ 来生成新的数据。
判别模型
判别模型关注的是对观测数据进行分类的决策边界,即学习决策函数 $Y = f(X)$。判别模型直接学习类别之间的决策边界,而不是对数据的生成过程进行建模。
区别
- 生成模型: 学习数据的生成过程,可以用于生成新的样本。
- 判别模型: 学习类别之间的决策边界,关注分类问题。
朴素贝叶斯分类器通常被归类为==生成模型==,因为它试图学习类别的生成过程。相比之下,逻辑回归和支持向量机等算法通常被归类为判别模型,因为它们关注的是决策边界而不是数据的生成过程。
Support Vector Machine 支持向量机
根本思想: Maximizing margin (lec10 第 13、 14 页)
支持向量机(Support Vector Machine,SVM)之所以被视为自带正则化项,与其优化目标和决策边界的特性有关。在支持向量机中,存在一个关键的超参数 $C$,它控制了对误分类的惩罚程度。这个超参数 $C$ 在 SVM 的优化问题中起到了类似于正则化强度的作用。
SVM 的优化目标
SVM 的优化目标是找到一个最大间隔的决策边界,并通过最小化误分类点来优化模型。具体而言,SVM 的优化目标可以表示为:
$\min{w, b} \frac{1}{2} ||w||^2 + C \sum{i=1}^{m} \max(0, 1 - y_i(w \cdot x_i + b))$
其中:
- $w$ 是权重向量。
- $b$ 是偏置项。
- $C$ 是一个正则化超参数。
- $||w||^2$ 表示权重向量的 L2 范数。
- $y_i$ 是第 $i$ 个样本的真实标签。
- $x_i$ 是第 $i$ 个样本的特征向量。
正则化效应
间隔最大化: SVM 的优化目标的第一项 $\frac{1}{2} ||w||^2$ 表示最大化决策边界的间隔,使得模型更加泛化。
误分类惩罚: 通过 $\sum_{i=1}^{m} \max(0, 1 - y_i(w \cdot x_i + b))$ 项,对误分类的点进行了惩罚。这一项的大小受到 $C$ 的调节,当 $C$ 较大时,对误分类的惩罚较重,模型更倾向于拟合训练数据,可能导致过拟合;而当 $C$ 较小时,对误分类的惩罚较轻,模型更倾向于寻找更大的间隔,从而提高泛化性能。
通过调节超参数 $C$,可以在最大间隔和对误分类点的惩罚之间找到平衡,实现对模型的正则化。较大的 $C$ 值会导致更少的误分类但可能产生较小的间隔,而较小的 $C$ 值则可能允许更大的间隔但可能容忍更多的误分类。这种权衡使得 SVM 在一定程度上自带正则化项,帮助控制模型的复杂度,避免过度拟合。
硬间隔 SVM(Hard Margin SVM)
硬间隔支持向量机是 SVM 的一种形式,其中决策边界被要求完全不允许任何训练点出现在边界之内。硬间隔 SVM 适用于训练数据是线性可分的情况,即存在一个超平面能够完美地将不同类别的样本分开。
硬间隔 SVM 的优化目标是最大化两类样本点到决策边界的间隔,同时满足所有样本点都在正确的一侧,不允许出现分类错误。
软间隔 SVM(Soft Margin SVM)
软间隔支持向量机是为了处理训练数据不是线性可分的情况而提出的。在实际应用中,数据可能包含噪声或异常点,硬间隔 SVM 对这些数据非常敏感。因此,软间隔 SVM 允许一些样本出现在决策边界的错误一侧,并引入了松弛因子(slack variable)来衡量分类错误的程度。
e.g 以下关于 SVM 的描述中,错误的项是?
==A、==硬间隔(hard margin):如果训练数据是线性可分的,我们可以选择两个平行的超平面来分隔这两类数据,使得超平面之间的距离尽可能大。
B、硬间隔:如果训练数据是线性可分的,我们可以选择两个平行的超平面来分隔这两类数据,使得超平面之间的距离尽可能小。
C、软间隔(soft margin):不允许有数据点位于超平面的错误一侧以及边距和超平面的正确一侧之间。
==D、==软间隔:允许一些数据点停留在超平面的错误一侧,以及边距和超平面的正确一侧之间。
松弛因子和 Hinge Loss
松弛因子(Slack Variable)
松弛因子是软间隔 SVM 中引入的变量,用于度量每个样本点是否违反了间隔要求。对于每个样本点,引入一个松弛因子,表示其允许偏离正确一侧的程度。优化目标包含最小化松弛因子的部分,以平衡最大化间隔和最小化分类错误之间的关系。
Hinge Loss
Hinge Loss 是用于衡量分类错误的损失函数,通常与松弛因子一起使用。
对于第 $i$ 个样本点,其 Hinge Loss 定义为:
$\max(0, 1 - y_i \cdot f(x_i))$
其中 $y_i$ 是样本的真实标签,$f(x_i)$ 是样本点到决策边界的距离。Hinge Loss 为正表示分类错误,为零表示分类正确。
支持向量
支持向量是指在 SVM 中==用于定义决策边界的训练样本点==。
在硬间隔 SVM 中,支持向量是那些恰好落在边界上的点,而在软间隔 SVM 中,支持向量可能是那些位于间隔错误一侧或在边界上的点。支持向量对决策边界的位置具有关键性的影响。
5. 对偶问题和 Kernel Trick
对偶问题
将原始的优化问题转换为对偶问题的好处是可以更有效地使用核技巧,同时在某些情况下可以简化计算。对偶问题的解通常包含一个称为拉格朗日乘子(Lagrange Multiplier)的变量,每个训练样本对应一个拉格朗日乘子。
Kernel Trick
核技巧是通过将原始特征空间映射到高维空间,而无需显式计算映射后的特征向量,从而在计算中引入非线性性。核函数定义了在原始特征空间中计算两个样本点之间的内积,即 $K(x_i, x_j) = \phi(x_i)^T \cdot \phi(x_j)$。
常用的核函数包括线性核、多项式核、高斯核(RBF核)等。通过使用核函数,可以在不显式计算高维特征向量的情况下,将 SVM 扩展到非线性问题。
NN
感知机
感知机是一种简单的神经网络结构,包含输入层和输出层,没有隐藏层。它可以用于二分类问题。
感知机的关键特点是其决策边界是线性的。它通过学习权重和偏置项,对输入进行线性加权求和,然后通过激活函数(通常是阶跃函数)进行输出。
多层感知机
多层感知机(MLP)包含输入层、一个或多个隐藏层以及输出层。每一层都由多个神经元组成,每个神经元都与前一层的所有神经元连接,权重和偏置项用于调整连接强度。
由于多层感知机具有隐藏层,它能够学习非线性关系。通过引入非线性激活函数(如ReLU、Sigmoid或Tanh),神经网络可以捕捉和学习输入之间更为复杂的关系,从而解决非线性问题。
反向传播算法的基本思想
反向传播算法
反向传播(Backpropagation)是训练神经网络的一种常用算法。其基本思想是通过将网络的输出与真实标签之间的误差反向传播回网络,调整网络参数以最小化误差。
基本步骤
- 前向传播(Forward Propagation): 将输入数据通过网络进行正向传播,计算每一层的输出。
- 计算误差(Compute Loss): 计算网络输出与真实标签之间的误差。
- 反向传播(Backward Propagation): 将误差反向传播回网络,计算每个参数对误差的贡献。
- 更新参数(Update Parameters): 使用梯度下降等优化算法,更新网络参数以减小误差。
梯度下降
梯度下降是优化算法的一种,用于最小化损失函数。在反向传播中,计算每个参数对损失函数的梯度,然后更新参数以减小梯度。这样的迭代过程将逐渐使网络收敛到局部最小值,使得网络的输出更接近真实标签。
激活函数的导数
在反向传播中,需要计算每个神经元的梯度,而这通常涉及到激活函数的导数。不同的激活函数有不同的导数计算方式,例如,Sigmoid 函数的导数可以通过 Sigmoid 函数的输出直接计算。
强化学习
(1) 马尔可夫决策过程(MDP)的定义(Lec13 第 13 页), value/utility 的定义, policy的定义
(2) 理解 value iteration 和 policy iteration 的计算过程。 Value iteration 的计算(公式在P29,课堂上讲了个例子 P30-31); Policy iteration 的计算(P71)
马尔可夫决策过程(MDP)
MDP 的定义
马尔可夫决策过程是强化学习问题的数学建模框架,它包括以下要素:
- 状态空间 $S$: 描述问题中所有可能的状态的集合。
- 动作空间 $A$: 描述智能体可以采取的所有可能动作的集合。
- 转移概率 $P$: 描述在某个状态下执行某个动作后,下一个状态的概率分布。
- 奖励函数 $R$: 描述在某个状态执行某个动作后,智能体所获得的即时奖励。
- 折扣因子 $\gamma$: 描述未来奖励的衰减因子。
Value/Utility 和 Policy 的定义
- Value/Utility $V(s)$: 表示从状态 $s$ 出发,按照某个策略执行动作,累计获得的期望累积奖励。
- Policy $\pi$: 表示在每个状态下选择的动作策略。可以是确定性策略,也可以是随机策略。
Value Iteration 和 Policy Iteration
Value Iteration 的计算过程
Value Iteration 是一种动态规划算法,用于找到最优策略和最优值函数。其计算过程如下:
- 初始化值函数 $V(s)$: 将所有状态的值初始化为零或随机值。
- 迭代更新:
- 对于每个状态 $s$,计算新的值函数 $V’(s)$:
$V’(s) = \maxa \left( R(s, a) + \gamma \sum{s’} P(s’ | s, a) \cdot V(s’) \right)$ - 更新值函数:$V(s) \leftarrow V’(s)$
- 对于每个状态 $s$,计算新的值函数 $V’(s)$:
- 重复迭代直到收敛。
Policy Iteration 的计算过程
Policy Iteration 通过交替进行策略评估和策略改进来找到最优策略。其计算过程如下:
- 初始化策略 $\pi$: 可以是任意初始策略。
- 策略评估:
- 使用当前策略 $\pi$ 进行值函数的评估,得到值函数 $V^\pi$:
$V^\pi(s) = R(s, \pi(s)) + \gamma \sum_{s’} P(s’ | s, \pi(s)) \cdot V^\pi(s’)$
- 使用当前策略 $\pi$ 进行值函数的评估,得到值函数 $V^\pi$:
- 策略改进:
- 在每个状态 $s$ 上选择使得下一个状态的值更大的动作 $a$:
$\pi’(s) = \arg \maxa \left( R(s, a) + \gamma \sum{s’} P(s’ | s, a) \cdot V^\pi(s’) \right)$ - 更新策略:$\pi \leftarrow \pi’$
- 在每个状态 $s$ 上选择使得下一个状态的值更大的动作 $a$:
- 重复策略评估和策略改进直到策略不再变化。
用神经网络进行强化学习
神经网络在强化学习中可以用于近似值函数或策略函数。具体而言,可以使用深度 Q 网络(DQN)来近似状态-动作值函数,也可以使用策略梯度方法来近似策略函数。这样的神经网络可以通过与环境的交互进行训练,以逐步提高其在任务中的性能。