现代操作系统2-CS2310
Slides8 Memory
MMU
relocation register
CPU -(Logical Addr)> MMU -(Physical Address)> memory
Memory Management
Contiguous memory allocation

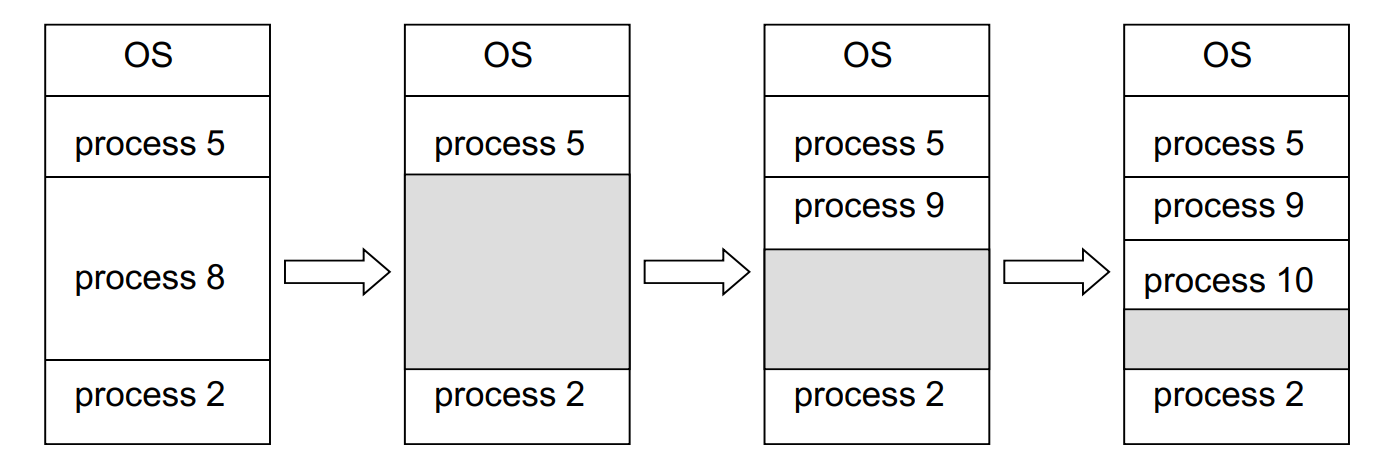
Multiple-partition allocation
- When a process arrives, it is allocated memory from a hole large enough to accommodate it
- Process exiting frees its partition, adjacent free partitions combined
- Operating system maintains information about:
- First-fit
- Best-fit
- Allocate the smallest hole that is big enough
- must search entire list, unless ordered by size
- Produces the smallest leftover hole
- Worst-fit
- External Fragmentation – total memory space exists to satisfy a request,
but it is not contiguous - Internal Fragmentation
- allocated memory may be slightly larger than requested memory; this size difference is memory internal to a partition, but not being used
- First fit analysis reveals that given N blocks allocated, another 0.5 N blocks lost to fragmentation
- 1/3 may be unusable -> 50-percent rule
- A solution : Compaction -> reduce external fragmentation
- shuffle memory
- possible only if relocation is dynamic, done at execution time
- Another solution : Permit noncontiguous memory allocation
- allow noncontiguous physical address space
- divide physical memory into fix-sized blocks —FRAMES
- size is power of 2, 512b - 16Mb
- keep track of all free frames
- divide logical memory into same sized blocks —PAGES
- to run a program of N pages -> find N free frames
- maintain a page table to translate addresses
(still have internal fragmentation)
-> P -> F translator
Implement
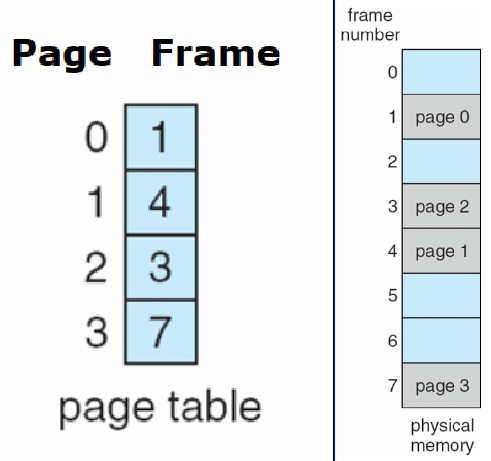
- Address generated by CPU is divided into:
- Page number (p)
- used as an index into a page table, which contains base address of each page in physical memory
- Page offset (d)
- combined with base address to define the physical
memory address that is sent to the memory unit
Page table is kept in main memory
- combined with base address to define the physical
- Page number (p)
- Page-table base register (PTBR) points to the page table
- Page-table length register (PTLR) indicates size of the page table
- In this scheme every data/instruction access requires two memory
accesses
-> - associative memory or translation lookaside buffers (TLBs)
- eg. 2-level paging table -> forward-mapped page table
- 10-bit page num*2 + 12-bit offset
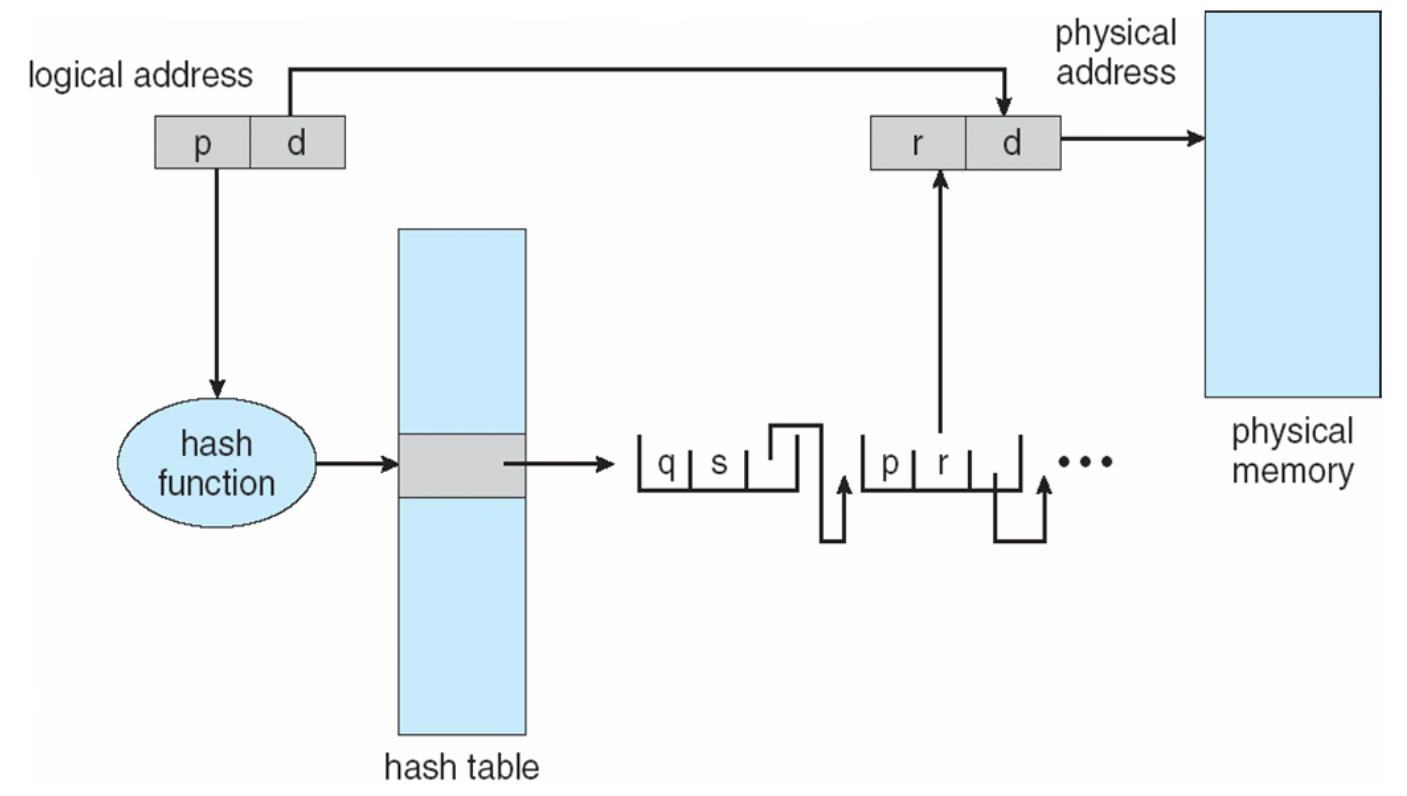
Hashed Page Tables
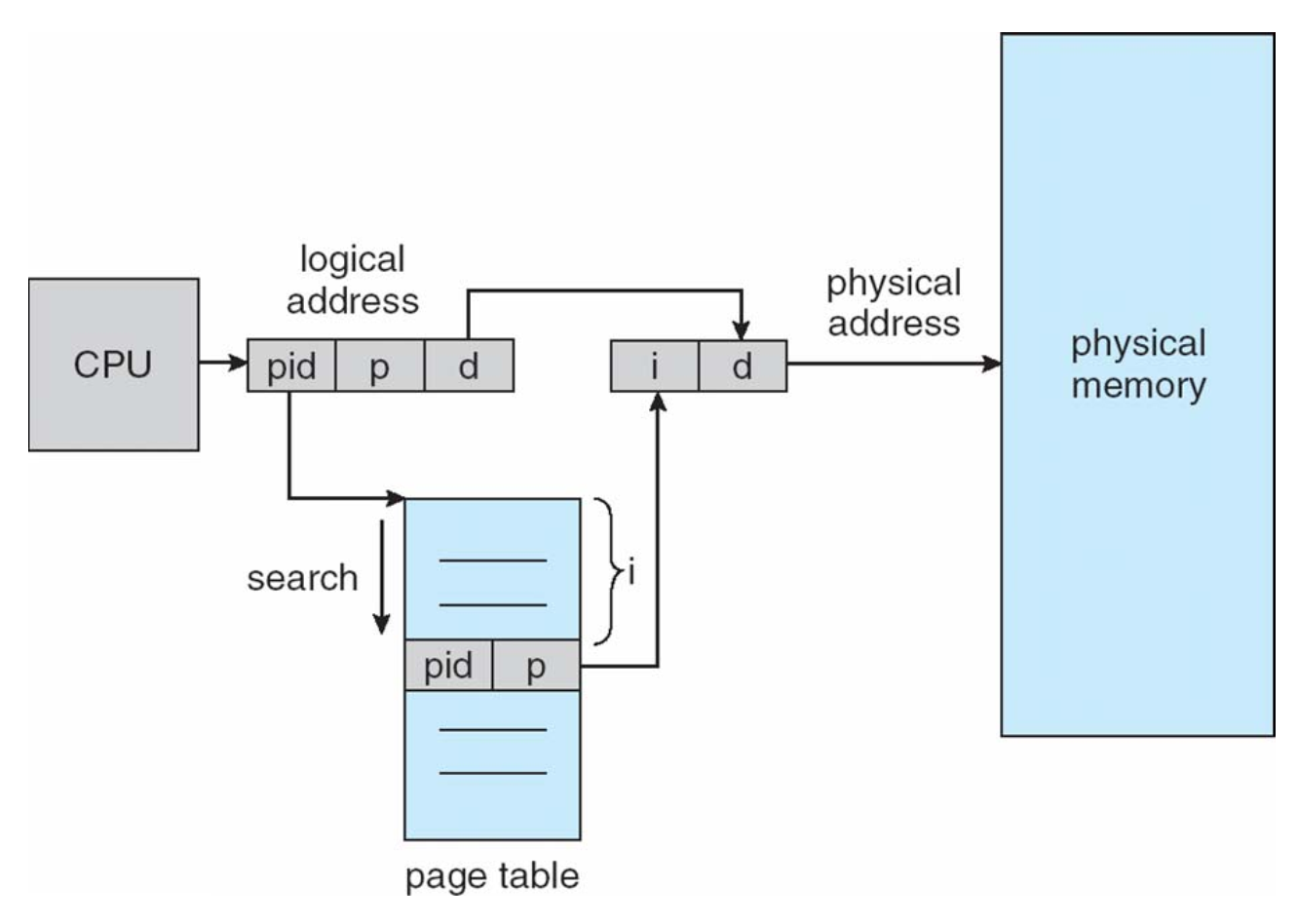
Inverted Page Tables
まとめ
Hierarchical Page Tables,Hashed Page Tables和Inverted Page Tables都是操作系统中用于将虚拟地址映射到物理地址的数据结构。
Hierarchical Page Tables是一种多层表,将虚拟地址分成多个部分,每个部分都有一个表。
Hashed Page Tables是一种哈希页表,虚拟页号在虚拟地址中被哈希到哈希表中。
Inverted Page Tables是一种全局页表,由操作系统维护,用于所有进程。在Inverted Page Tables中,条目数等于主存中的帧数。与传统的页表相比,Inverted Page Tables具有更小的内存占用,但查找时间更长。
这些数据结构在许多操作系统中都有使用。例如,Linux使用了Inverted Page Tables,而Windows使用了Hierarchical Page Tables。Hashed Page Tables也被许多操作系统使用,例如FreeBSD和Solaris。Segmentation
Memory-management scheme that supports user view of memory
Logical address consists of a two tuple:
- 10-bit page num*2 + 12-bit offset
- Segment table – maps two-dimensional physical addresses;
- each table entry has:
- base: contains the starting physical address where the segments
reside in memory - limit: specifies the length of the segment
- base: contains the starting physical address where the segments
- Segment-table base register (STBR) -> segment table’s location in memory
- Segment-table length register (STLR) indicates number of segments
used by a program; segment number s is legal if s < STLRSlides9 Virtual Memory
- Virtual Address Space
- Enables sparse address spaces with holes left for growth, dynamically linked libraries, etc
- easily shared during fork()
- COW(Copy-on-write)
- Lazy Swapper (Pager) :never swaps a page into memory unless page will
be needed
- Valid-Invalid Bit
- each table entry associates with a ~ bit
- V -> memory resident ({address} v) , i -> not-in-memory ({\ i})
- entry is i -> page fault
- Page Fault
- if there is a reference to a page and the page is not in memory (i), the
reference will trap to operating system
- if there is a reference to a page and the page is not in memory (i), the
- Operating system looks at page table to decide:
Invalid reference -> abort / Just not in memory - Get empty frame
- Swap page into frame via scheduled disk operation
- Reset tables to indicate page now in memory (Set validation bit = v)
- Restart the instruction that caused the page fault
-> what if there’s no Free Frame?
- Page replacement
an algorithm which will result in minimum number of page faults
- Find the location of the desired page on disk
- Find a free frame:
- If there is a free frame, use it
- If there is no free frame, use a page replacement algorithm to select a
victim frame - Write victim frame to disk if dirty (Use modify (dirty) bit to reduce overhead of page transfers)
- Bring the desired page into the (newly) free frame; update the page and
frame tables
- Continue the process by restarting the instruction that caused the trap
- How to choose ‘desired pages’ : Page-Replacement Algorithms
- FIFO
Slides10 Mass-Storage Systems
Disk stucture
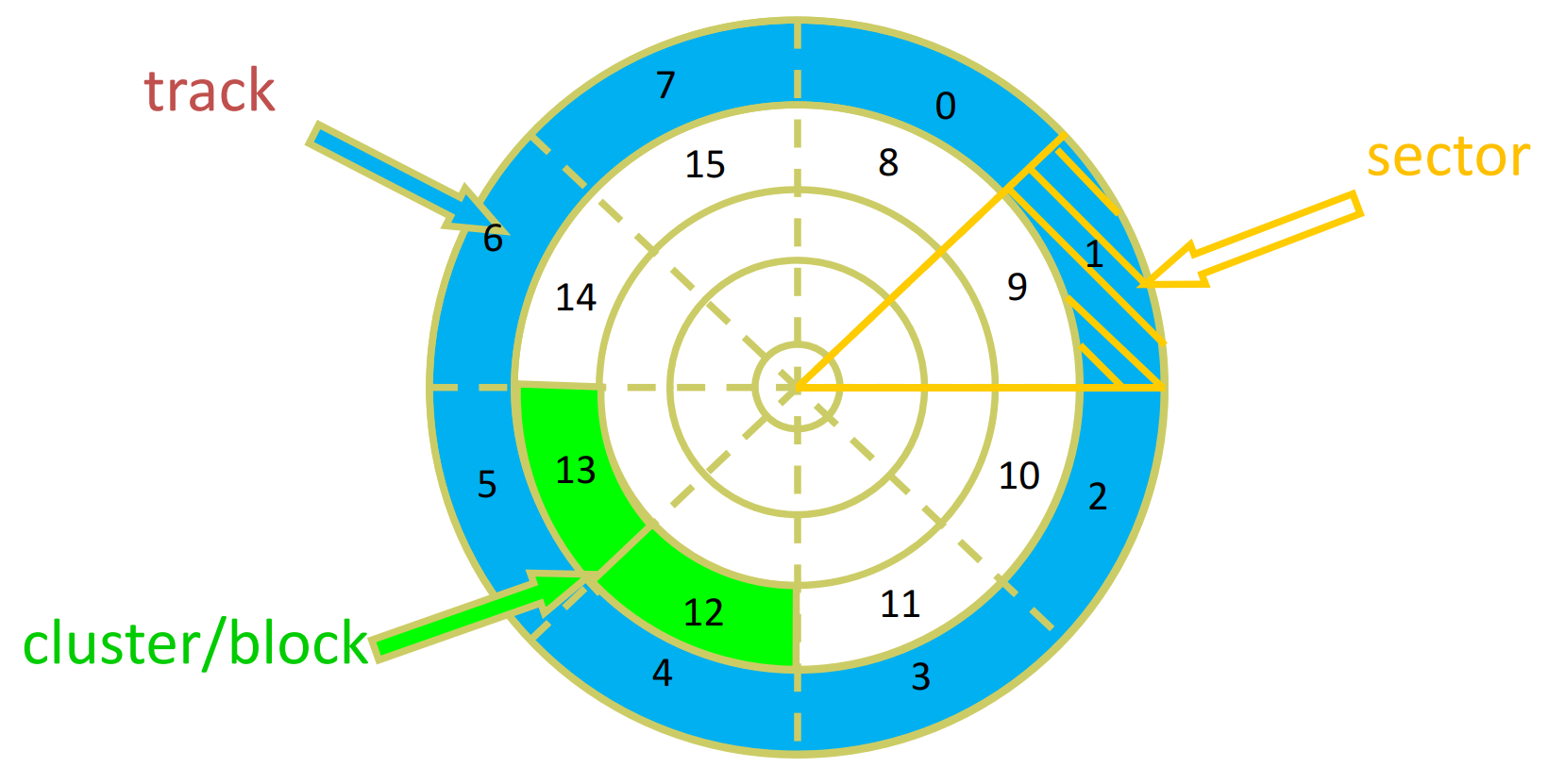
-> addressed as large 1-d arrays of logical blocks (smallest unit)
- The 1-dimensional array of logical blocks is mapped into the sectors of the disk sequentially
- Sector 0 is the first sector of the first track on the outermost cylinder
- Mapping proceeds in order through that track, then the rest of the tracks in that cylinder, and then through the rest of the cylinders from outermost to innermost
- Difficulty in mapping from logical to physical address:
- Except for bad sectors
- Non-constant # of sectors per track via constant angular velocity
Overview of Mass Storage Structure
- Magnetic disks provide bulk of secondary storage of modern computers
- Drives rotate at 60 to 250 times per second
- Transfer rate is rate at which data flows between drive and computer
- Positioning time (random-access time) is time to move disk arm to desired cylinder (seek time) and time for desired sector to rotate under the disk head (rotational latency)
Disk-Scheduling Algorithms
Idle disk can immediately work on I/O request, busy disk means work must
be queued (Optimization algorithms only make sense when a queue exists)
- FCFS
按queue处理 - SSTF
Shortest Seek Time First selects the request with the minimum seek time from the current head position (当前最近) - SCAN
The disk arm starts at one end of the disk, and moves toward the other end,
servicing requests until it gets to the other end of the disk, where the head
movement is reversed and service continues. - C-SCAN
The head moves from one end of the disk to the other, servicing requests as it goes. When it reaches the other end, it immediately returns to the beginning of the disk, without servicing any requests on the return trip. - C-LOOK
Similar to C-SCAN, but doesn’t reach the two ends.
Arm only goes as far as the last request in each direction, then reverses direction immediately, without first going all the way to the end of the disk
-》 in C-XXXX , arm services always occur in one direction. when they are moving are the opposite direction, they ‘immediately returns‘.
SSD vs HDD
Nonvolatile memory devices
- disk-drive like -> solid-state disks (SSD)
- (Other forms include USB drives (thumb drive, flash drive), DRAM stick, and main storage in devices like smartphones )
- Storage capacity / price
capacity: HDD usually > SSD
price : SDD usually > HDD (per MB)magnetic disks (HDD) hold much more data. - Reliability
- SSD > HDD
- SSDs have no moving parts (like magnetic disks and read/write heads) ->less possible to damage
- SSD > HDD
- ==Lifespan==
- SSD << HDD
- -> SSD need to be carefully managed (storage units have a certain erasing and writing life) -> disk management
- LET’S TALK ABOUT IT LATER
- Speed
- SSD >> HDD
- No moving parts, so no seek time or rotational latency
- Bus speed
- SSD requires a direct connection to a high-speed bus (such as PCI) for maximum performance
- (while HDDs are not subject to this limitation)
- ==Disk management==
- SSDs need to implement complex flash controller algorithms, such as garbage collection, wear leveling, etc., to manage storage space.
- HDDs, on the other hand, require low-level formatting (physical formatting) and logical formatting (logical formatting) to create file systems and deal with problems such as bad blocks.
- LET’S TALK ABOUT IT LATER
- ==Space management==
- In HDD, the file system usually uses clusters (簇) to manage disk space, and the size of the cluster is usually fixed.
- In SSD, due to the complexity of its internal data management method, the file system usually needs to adopt different space management strategies, such as TRIM command and garbage collection (Garbage Collection), etc., to maintain the performance and lifespan of SSD.
- LET’S TALK ABOUT IT LATER
Space & Disk Management
More About Clusters, Blocks and Tracks …
HDD
- 簇(cluster):簇是一组相邻的扇区(sector)的集合,是文件系统中的最小单位。
- 块(block):块是磁盘上用于存储数据的逻辑单位,通常由多个扇区组成。块是文件系统管理磁盘空间的基本单位(读写数据的基本单位)。
- 磁道(track):磁道是磁盘上的一个圆形轨道,由多个扇区组成。磁道是磁盘上进行数据读写的基本单位,磁头(head)在磁道上移动,可以读取或写入扇区中的数据。(只属于HDD的物理概念,SSD不存在这个概念)
SSD - 页(page):页是SSD中最小的可读写单元,通常为4KB或8KB大小。
- 块(block)类似HHD。由多个页构成。为了增大擦除时一次性操作的块的大小延长寿命,在SSD中通常更大,通常为128KB或256KB大小。(理由后面细说)
HDD
- -> Dividing a disk into sectors that the disk controller can read and write
- Each sector can hold header information + data + error correction code (ECC)
- Usually 512b data but can be selectable
- OS needs to record its own data structures on the disk
- Part groups of cylinders, each treated as a logical disk
- Logical formatting or “making a file system”
- To increase efficiency most file systems group blocks into clusters
Disk I/O done in blocks ; File I/O done in clusters
- Boot block initializes system
- The bootstrap is stored in ROM
- Bootstrap loader program stored in boot blocks of boot partition
- Methods such as sector sparing used to handle bad blocks
MBR
- Boot code + partition table (contains pointer to boot partition)
SSD
- Read and written in “page” increments (think sector)
- ==but can’t overwrite in place==
- Must first be erased, and erases happen in larger “block” increments
- 要修改或擦除一个页,需要先将整个块读取到内存中,然后进行修改或擦除,最后再将整个块写回SSD。(所以SSD的块常常比HHD大的多,以增大每次擦写的大小、减小擦写次数)
- Can only be erased a limited number of times before worn out ~ 100,000
- Life span measured in drive writes per day (DWPD)
- A 1TB NAND drive with rating of 5DWPD is expected to have 5TB per day written within warrantee period without failing
- 块级别的操作对于SSD的性能和寿命管理是非常重要的。-》
- ==but can’t overwrite in place==
NAND Flash Controller Algorithms
- With no overwrite, pages end up with mix of valid and invalid data. We need ways to manage them:
- flash translation layer (FTL) table (a part of NAND flash)
- Track which logical blocks are valid
- TRIM (a instruction involving SSD and OS)
- inform which logical blocks are invalid more flexibly and timely
- Garbage collection (GC)
- Allocates overprovisioning to provide working space for GC
- 垃圾回收是SSD内部的一种自动化操作,用于清理和整理闲置和无效的页。当文件被删除或修改时,SSD的页可能会变得闲置或无效,但这些页实际上仍然占据着宝贵的存储空间。垃圾回收操作会定期或在需要时将这些闲置和无效的页整理到一起,并执行擦除操作,以便可以重新分配给新的数据,从而提高SSD的存储效率。
- flash translation layer (FTL) table (a part of NAND flash)
- Write Wear Leveling (均衡写入耗损)
- Each cell has lifespan, try to write equally to all cells
- 这可以通过在写入新数据时选择尽可能少使用写入次数较多的块,或将写入数据随机分布到多个块中来实现。
Disk Attachment
- Drive attached to computer via I/O bus
- Host controller in computer uses bus to talk to disk controller built into drive
- Busses vary (protocols vary)
- 接口协议规定了硬件设备之间的通信协议和通信方式,而数据总线BUS则是物理连接这些设备之间的通信通道。
- including EIDE, ATA, SATA, USB, SCSI, Fiber Channel, SAS, Firewire…
- 家用计算机的CPU多使用PCI、SATA等接口协议,FC更多用于企业计算机和数据中心环境。
- SCSI(Small Computer System Interface)
- 过去比较常见
- a bus, up to 16 devices on one cable
- SCSI initiator 发起器 requests operation 发送操作请求 and SCSI targets 目标设备 perform tasks
- Each target can have up to 8 logical units (disks attached to device controller)
- FC (Fiber Channel) 光纤通道
- a high-speed serial architecture
- Can be switched fabric with 24-bit address space – the basis of storage area networks (SANs 存储区域网络) in which many hosts attach to many storage units
- 通常用于需要大规模存储和高速数据传输的应用场景
RAID
- Redundant Arrays of Independent Disks (RAIDs)
- RAID– multiple disk drives provides reliability via redundancy
- Mirroring ( -> a second copy)
- duplicate every disk
- Parity bit ( -> error-correcting bit)
- Mirroring ( -> a second copy)
- Parallel access to multiple disk improves performance
- Bit-level striping
- split the bits of each byte across multiple disks
- block-level striping
- blocks of a file are striped across multiple disks
- Bit-level striping
- RAID is arranged into seven or more different levels
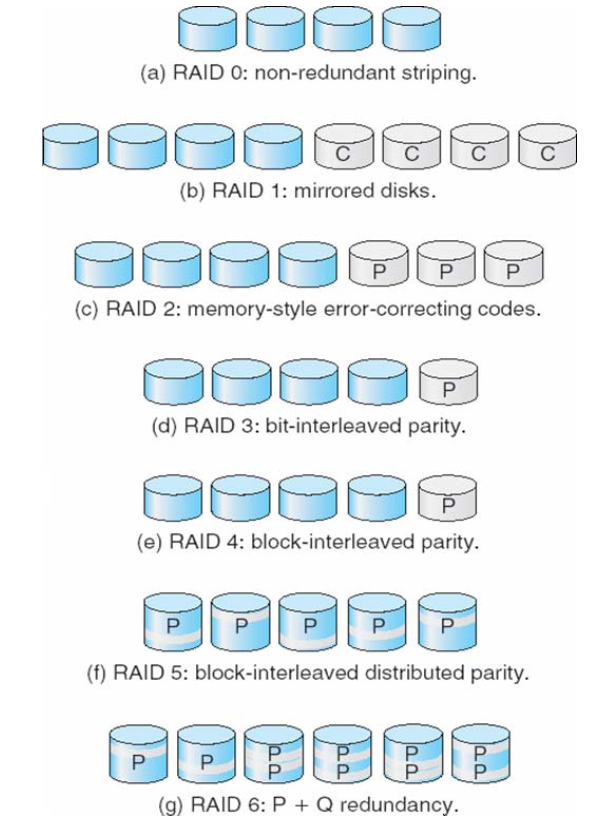
RAID 6: P + Q redundancy
- Reed-Solomon codes
- 2 bits of redundant data are stored for every 4 bits of data
- 在RAID6中,数据被分布式地存储在多个磁盘驱动器中,同时通过计算奇偶校验信息对数据进行冗余存储。RAID6采用两个奇偶校验盘(P和Q盘)来存储奇偶校验信息,从而实现了对两个磁盘驱动器的故障容忍。
交织分布奇偶校验(如RAID 5)和复制(如RAID 1)是两种不同的数据保护策略,它们在数据存储和容错方式上有以下区别:
- 存储方式:交织分布奇偶校验将奇偶校验信息分布存储在多个数据盘中,与原始数据分散存储在不同的盘上,从而实现数据和奇偶校验信息的分离存储。而复制方式则是将数据完全复制到多个独立的盘上,从而实现数据的冗余存储。
- 存储效率:交织分布奇偶校验在存储效率方面较为高效,因为它只需要使用一个额外的奇偶校验盘来存储校验信息,而原始数据可以充分利用所有的数据盘进行存储,从而提供了较高的存储容量。而复制方式则需要将数据完全复制到多个盘上,因此存储效率较低,通常只能提供50%的存储容量。
- 容错能力:交织分布奇偶校验和复制方式在容错能力上有所不同。交织分布奇偶校验可以容忍单个数据盘的故障,通过从其他数据盘和奇偶校验盘中恢复数据。而复制方式可以容忍多个数据盘的故障,因为数据被完全复制到多个盘上,只要其中一个副本可用,数据就可以被访问。
- 性能:交织分布奇偶校验和复制方式在性能方面也有所不同。交织分布奇偶校验在读性能上通常比较高,因为可以并行地从多个数据盘读取数据。但在写性能上可能受到奇偶校验盘的限制,因为写操作需要同时更新数据和奇偶校验信息。而复制方式在读性能上可能较低,因为需要从多个副本中选择一个进行读取,但在写性能上通常较高,因为数据只需要写入一个副本。
假设有一个包含4个数据盘和1个奇偶校验盘的RAID 5阵列,其中数据盘分别标记为D1、D2、D3、D4,奇偶校验盘标记为P。当一个数据盘出现故障时,可以通过从其他数据盘和奇偶校验盘中恢复数据。
例如,当D2数据盘出现故障时,需要从其他数据盘和奇偶校验盘中恢复D2上的数据。RAID 5使用异或(XOR)运算来生成奇偶校验信息,该运算具有可逆性,可以用于数据恢复。
假设D1、D3和D4上的数据分别为A、B和C,而P上的奇偶校验信息为A XOR B XOR C。现在需要恢复D2上的数据B,可以通过执行以下步骤:
- 从D1、D3和D4中读取对应位置上的数据,得到A、B和C的值。
- 从奇偶校验盘P中读取对应位置上的奇偶校验信息,得到A XOR B XOR C的值。
- 通过对已知的A、B和C的值以及A XOR B XOR C的值执行异或运算,即 (A XOR B XOR C) XOR (A XOR C) = B,得到D2上的数据B的值。
- 将得到的B的值写入到替换后的新数据盘D2上,完成数据恢复。
这样,通过从其他数据盘和奇偶校验盘中恢复数据,可以在某个数据盘出现故障时保护数据的完整性,并维持RAID 5阵列的可靠性和可用性。
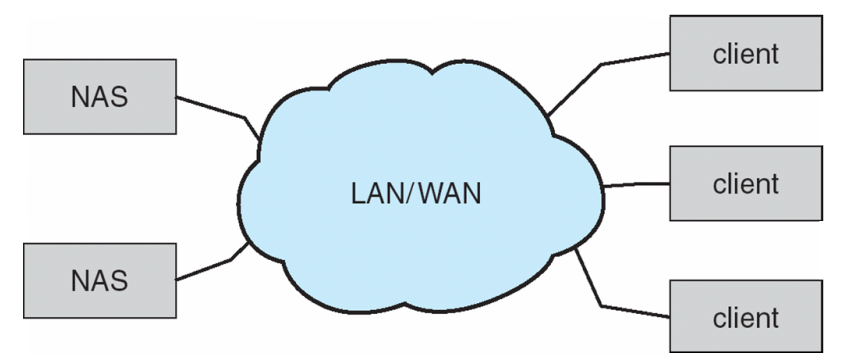
Network-Attached Storage
- Network-attached storage (NAS) is storage made available over a network rather than over a local connection (such as a bus)
- Remotely attaching to file systems
- Implemented via remote procedure calls (RPCs) between host and storage over typically TCP or UDP on IP network
- iSCSI protocol uses IP network to carry the SCSI protocol
- Remotely attaching to devices (blocks) -> virtual disks
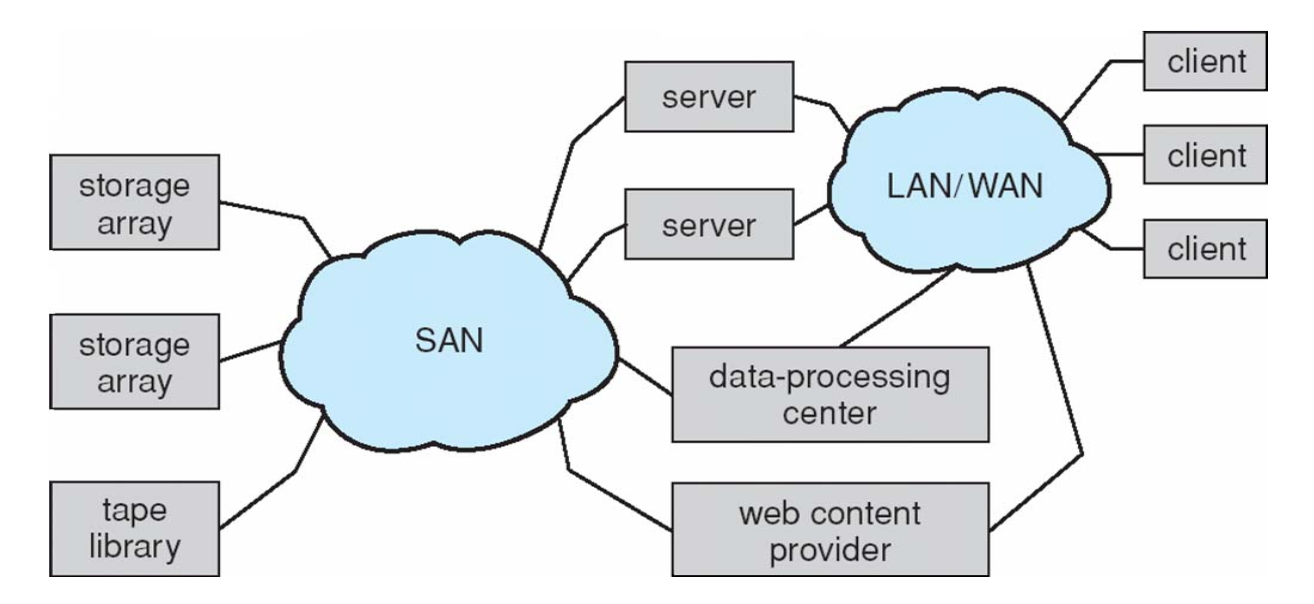
Storage Area Network(SAN)存储区域网络
- Common in large storage environments
- Multiple hosts attached to multiple storage arrays - flexible
- use high-speed buses,like Fibre Channel or iSCSI
Slides11 File System
File
A file is a named collection of related information that is recorded on
secondary storage.
- Attributes
- Name
- Identifier - unique tag(num) identifies file within file sys
- Type
- Text
- Source/object programs
- Executable programs
- Database records
- Graphic images
- Multimedia
- Location
- pointer to file location on device
- Size
- Protection
- controls who can do reading, writing, executing
- Time, Date, User identification
- Information about files are kept in the directory structure, which is
maintained on the disk
File operations
- Create
- Write
- Read
- Reposition within file
- Delete
Truncate
The other operations can be implemented by the primitive ones.
Open files
Several pieces of data are needed to manage open files.
- Open-file table
- tracks open files
- File pointer
- pointer to last read/write location, per process that has the file open
- File-open count
- counter of number of times a file is opened
- allow removal of data from open-file table when last process closes it
- Disk location of the file
- stores data access information
- Access rights
- provides per-process access mode information
- Protection: decide access rights
- File owner/creator should be able to control:
- what can be done
- by whom
- Types of access
- Read
- Write
- Execute
- Append
- Delete
- List
- Three classes of users
- owner, group, public (in unix/linux)
(windows: owner, group, others -> different names) - you can define the right by:
chgrp G game- g is a unique group name, you attach it to the file
chmod 761 game- 7 for owner, 6 for group, 1 for public
- owner, group, public (in unix/linux)
- File owner/creator should be able to control:
- Access methods
- Sequential access
- read/write next
- reset
- Direct access
- read/write n (n = relative block/byte number)
- position to n
- read/write next
- Sequential access
Disk Structure
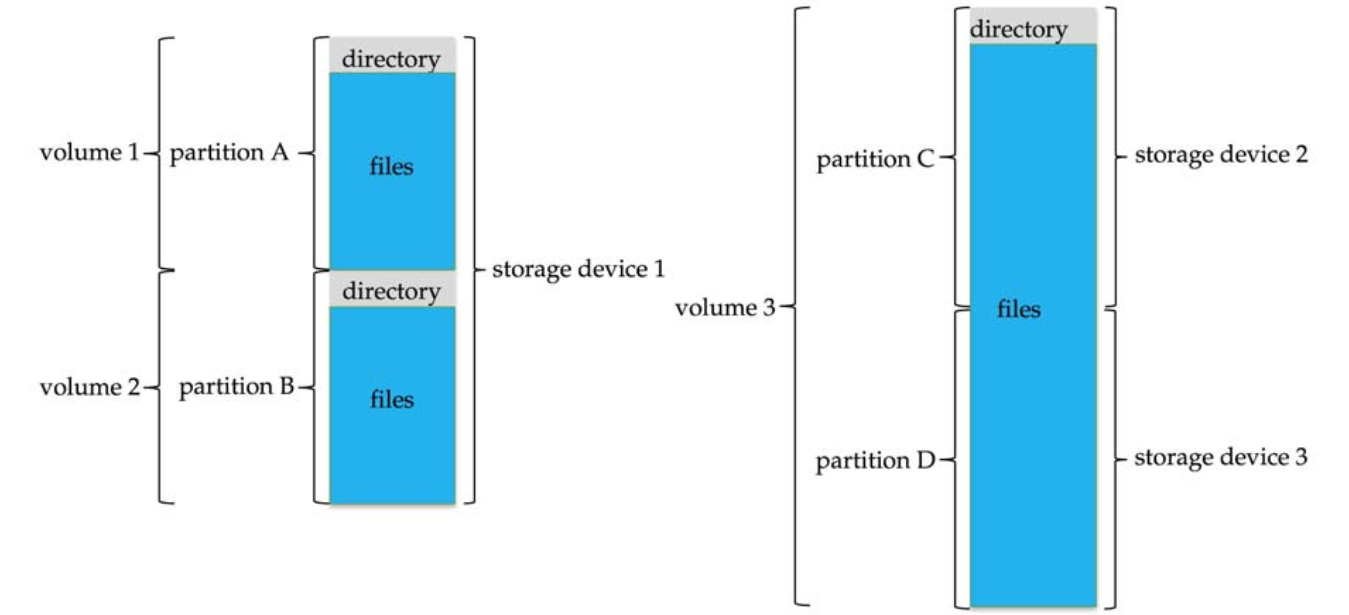
- Disk can be subdivided into partitions 分区 (minidisks, slices)
- Disks/partitions can be RAID protected against failure
- Disks/partitions can be used raw
- raw: without a file system, or formatted with a file system
- Entity 实体 containing file system known as a volume 卷
- Each volume tracks file system’s info in device directory 设备目录 or volume table of contents 卷目录
File Directory
Organize the Directory (Logically) to Obtain
- Efficiency – locating a file quickly
- Naming – convenient to users
- Two users can have same name for different files
- The same file can have several different names
- Grouping – logical grouping of files by properties, (e.g., all Java programs, all games, …)
Single-Level Directory
- A single directory for all users
- Efficiency problem
- Naming problem
- Protection of users’ private files
- Grouping problem
Two-Level Directory

- Separate directory for each user
- Can have the same file name for different user
- A little bit more efficient searching
- Path name
- No grouping capability
Tree-Stuctured Directory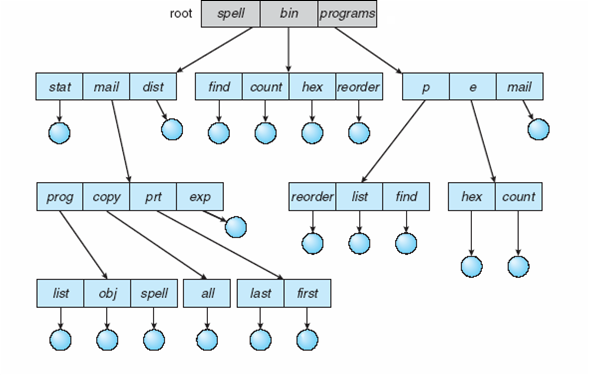
Acyclic-Graph Directories
Have shared subdirectories and files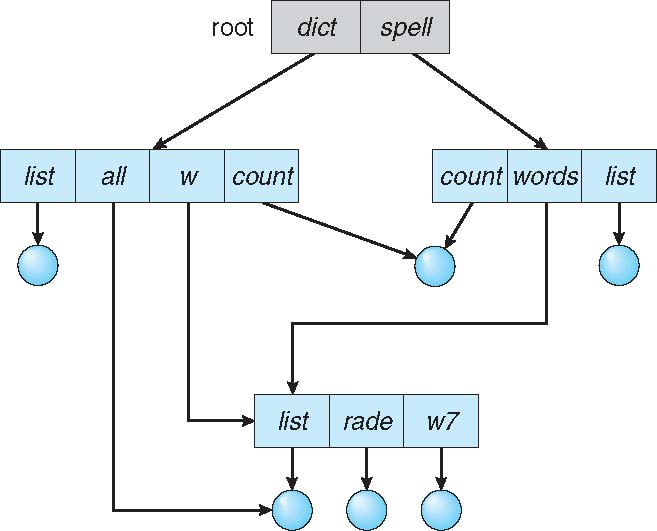 **
**
- Two different names (aliasing)
- New directory entry type
- Link – another name (pointer) to an existing file
- Resolve the link – follow pointer to locate the file
If dict deletes count -> dangling pointer
Solutions
- Backpointers, so we can delete all pointers
- Entry-hold-count solution
General Graph Directory
File Allocation Methods
An allocation method refers to how disk blocks are allocated for files
- Contiguous allocation
- Linked allocation
- Indexed allocation
Contiguous Allocation
- 连续分配 each file occupies a set of contiguous blocks
- Simple
- starting location (block #)
- length (number of blocks)
- Best performance in most cases
- Problems:
- Finding space for file
- Knowing file size
- External fragmentation 外部碎片
- need for compaction off-line (downtime) or on-line 需要离线(停机)整理碎片
- Simple
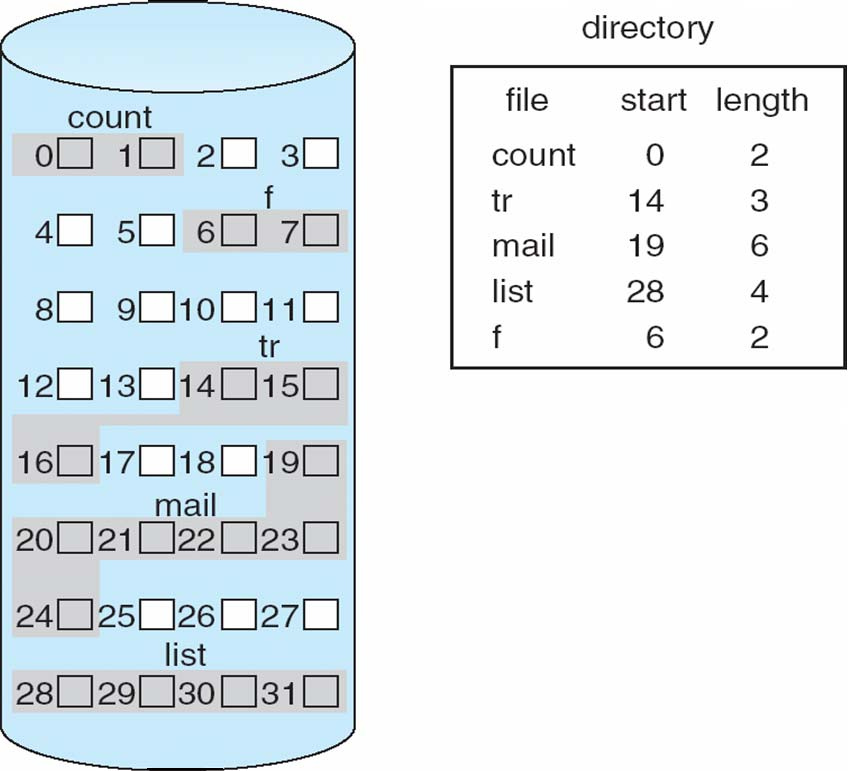
Linked Allocation
Each file is a linked list of disk blocks: blocks may be scattered
anywhere on the disk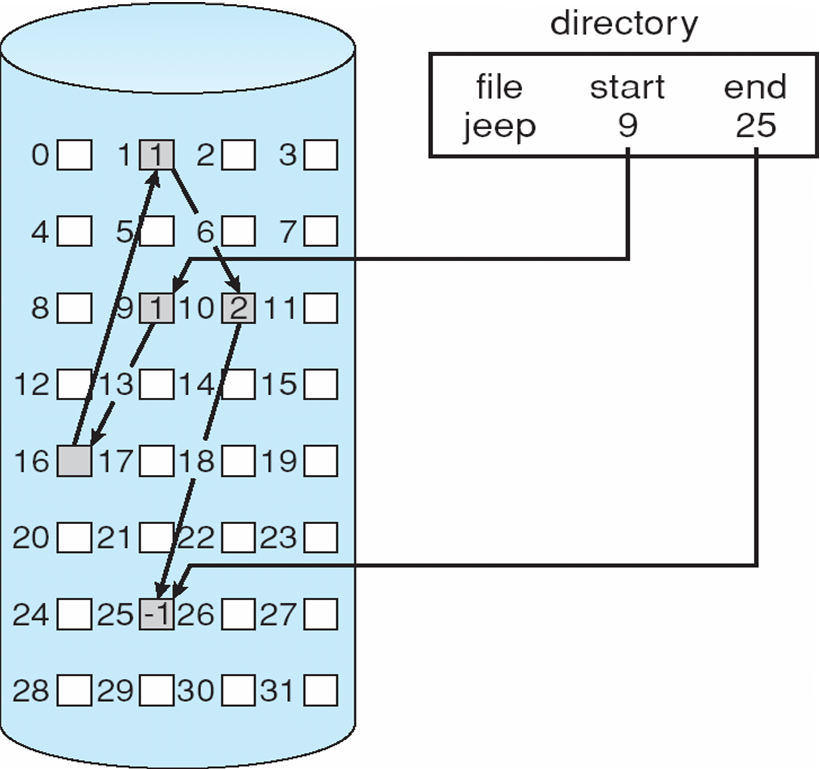
each file is a linked list of blocks
- Each block
- a pointer to next block
- file ends at nil pointer
- No external fragmentation
- Free space management system called when new block needed
- Improve efficiency by clustering blocks into groups but increases internal fragmentation
- Problem
- Reliability
- Locating a block can take many I/Os and disk seeks
File-Allocation Table (FAT)
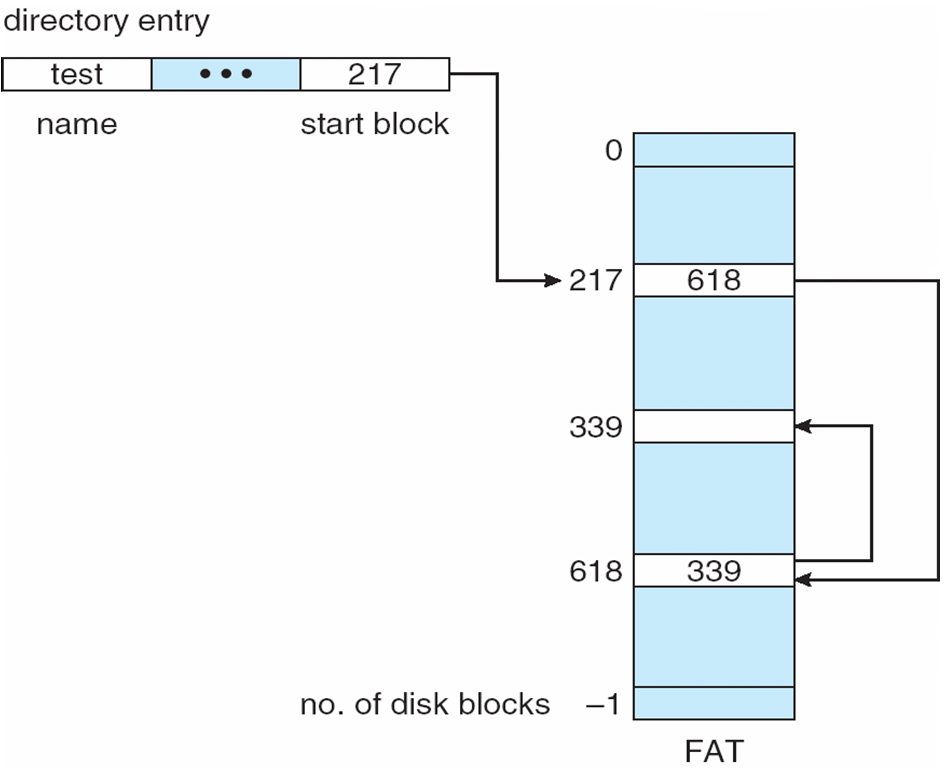
- Beginning of volume has a table, indexed by block number
- Records allocation information and status of file blocks or clusters
- Occupied
- Uses a linked list structure to link the occupied file blocks or clusters
- Unallocated
- Marked with corresponding status flags
- Occupied
- Records allocation information and status of file blocks or clusters
- Much like a linked list, but faster on disk and cacheable
New block allocation simple
DOS / Windows
FAT vs linked allocation
- 存储方式
- FAT文件系统
- 将整个文件的分配情况记录在文件分配表中
- 一次性读取整个文件的所有文件块地址到队列中,从而更好地进行访问规划
- 这对于机械硬盘等需要顺序访问且对等待队列的优化敏感的存储设备来说尤为重要
- 链式分配文件系统
- 逐个读取文件块,并且每个文件块只记录下一个文件块的位置信息。
- 需要不断地从磁盘读取下一个文件块的位置
- FAT文件系统
- 如何找空格子
- 都需要遍历获取已占用的格子的信息
- FAT:查询文件分配表直到找到未分配的块
- linked allocation:从文件系统的起始位置开始,沿着链表遍历已占用的文件块,直到找到一个未占用的文件块
- 这时,FAT就显著比linked allocation快
- 都需要遍历获取已占用的格子的信息
Indexed Allocation
Each file has its own index block(s) of pointers to its data blocks
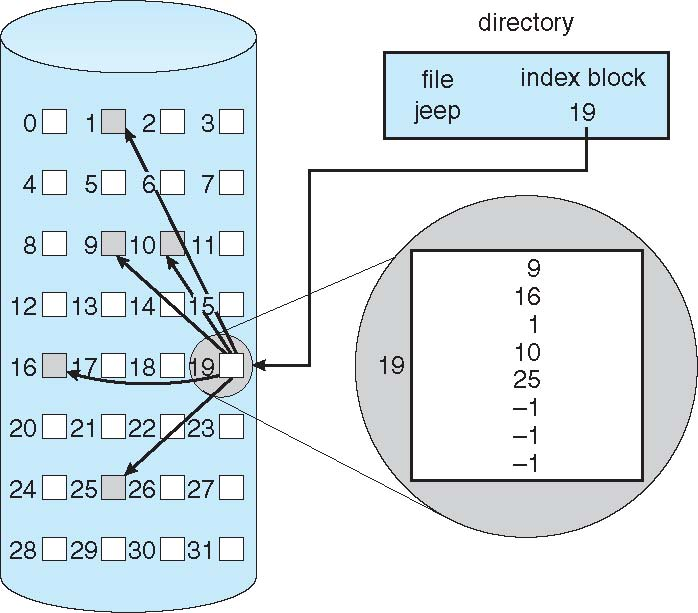
- Random access
- Without external fragmentation
- Need index table
I-node management

- I-nodes have limited size, so we need mutiple I-nodes linked
-> EXAMPLE
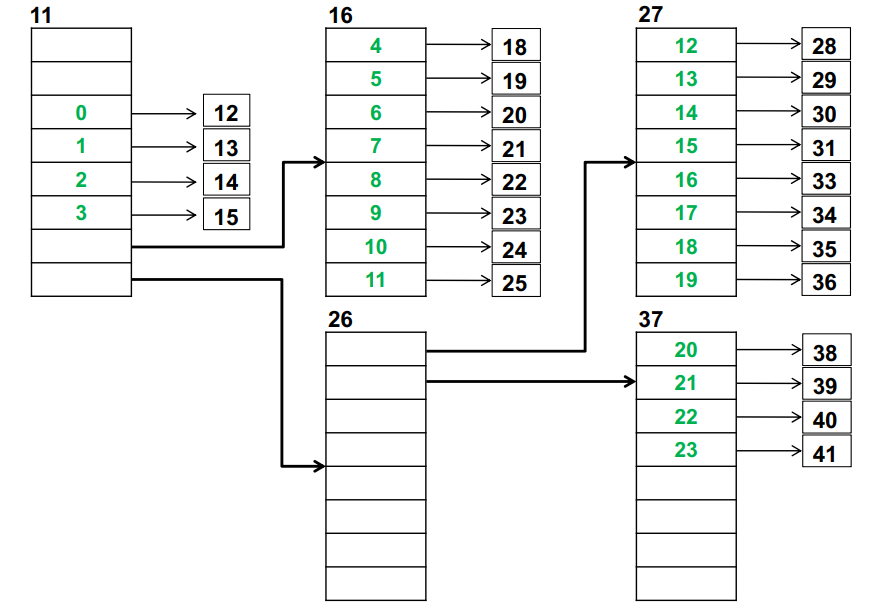
- Suppose a file system is constructed using blocks of 32 bytes. A pointer needs 4 bytes. The I-node structure is as follows (word, value):
| num | content | # |
|---|---|---|
| 0 | permission word | |
| 1 | direct block | linked to content directly |
| 2 | direct block | |
| 3 | direct block | |
| 4 | direct block | |
| 5 | direct block | |
| 6 | single-indirect | linked to another block |
| 7 | double-indirect | linked to a block which each 8 bytes points to a such unit |
- Assume that free blocks are allocated in logical order starting with block 11. Also it has been determined that blocks 17 and 32 are bad and cannot be allocated.
- - Draw a block diagram showing the structure of the I-node and the blocks that are allocated for
- Original file size of 3 blocks (IN THE 1ST NODE)
- Adding 4 blocks (single-indirect is enough)
- Adding 17 blocks (need double-indirect)
3+4blocks (4 in first I-node and 3 in single-indirect)
3+4+17blocks (4 in first I-node, 8 in single-indirect,11 in double-indirect )
Quiz
Suppose a file system is constructed using blocks of 32 bytes. A pointer
needs 4 bytes. The I-node structure is as follows (word, value):
num|content
—|—
0|permission word
1|file size
2|direct block
3|direct block
4|direct block
5|single-indirect
6|double-indirect
7|triple-indirect
- Assume that free blocks are allocated in logical order starting with block 100. Also it has been determined that blocks 107, 108, 109, and 112 are bad and cannot be allocated.
- Draw a block diagram showing the structure of the I-node and the blocks that are allocated for
- Original file size of 3 blocks
- Adding 7 blocks
- Adding 24 blocks
- Adding 64 blocks
Slides12 I/O System
I/O Hardware
Incredible variety of I/O devices
- Storage devices
- (disks, tapes)
- Transmission devices
- (network interface, Bluetooth)
- Human-interface devices
- (screen, keyboard, mouse, audio in and out)
- Storage devices
Common concepts – signals from I/O devices interface with computer
- Port 端口
- connection point for device
- Bus – a set of wires and a strictly defined protocol
- Daisy chain 链式连接
- (PC -> device A -> device B -> device C…)
- Shared direct access 共享直接访问
- I/O设备共用数据总线
- Daisy chain 链式连接
- Controller (host adapter 主机适配器)
- electronics that operate port, bus, device
- Port 端口
PCIE example
Hardware structure
registers
- place data/addr/commands
Addressing & instruction system
Memory mapped I/O
share address space with computer’s memory
r/w I/O just like memory
no special commandsIsolated I/O
seperate address space
need I/O & memory select lines
special commands
(以下段落内容与计算机组成重复)
I/O system
when cpu issues I/O request, cpu may have to wait for response? (low efficiency)
->
INTERRUPTS -> use interrupt handler to free cpu
- Checked by processor after each instruction
- Interrupt handler receives interrupts
- Nonmaskable
- reserved for events such as unrecoverable memory errors
- Maskable
- can be ignored or delayed, for device controllers to request service
- Interrupt vector to dispatch interrupt to correct handler
- Context switch at start and end
- Interrupt chaining
- Based on priority
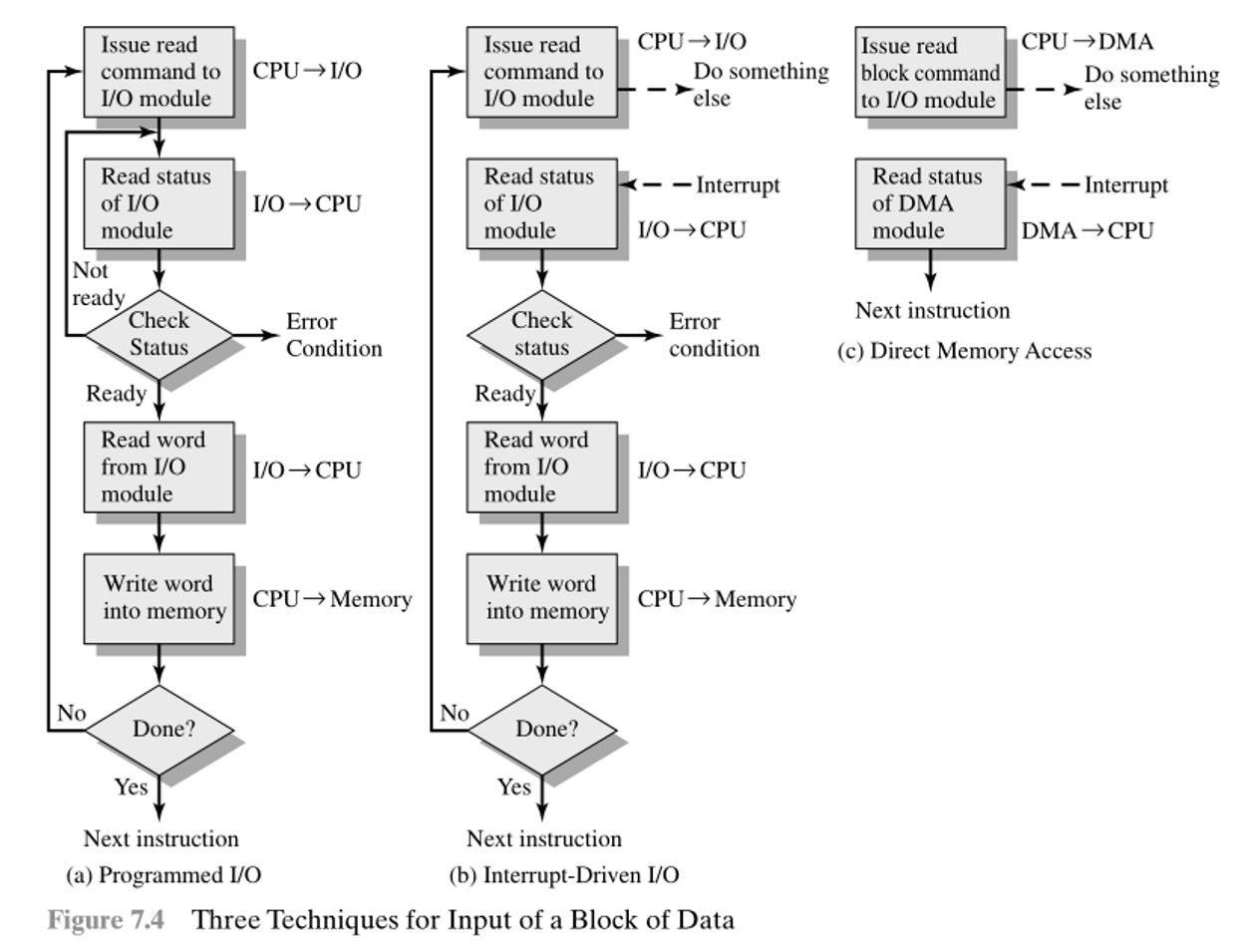
Programmed I/O
the CPU directly controls I/O hardware
Cpu:
issues request
continuously check response
read and write
Interrupt-Driven I/O
free CPU from I/O event
Cpu:
issue request
be interrupted when I/O module is ok
check read status and read, and write to memory
Direct Memory Access (DMA)
free CPU from I/O event & data writing
Cpu:
tells DMA the request
DMA interrupts Cpu when OK, and tells Cpu
| Interactionwith I/O Device | Programmed I/O | Interrupt-Driven I/O | Direct Memory Access |
|---|---|---|---|
| waiting for the device | software(instructions on cpu) | hardware | hardware |
| transfer device data to mem | software | software | hardware |
Slides13 Virtual Machines
Overview
- Fundamental idea
- abstract hardware of a single computer into several different execution environments
- Similar to layered approach
- But layer creates virtual system (virtual machine, or VM) on which operation systems or applications can run
- Several components
- Host 宿主机
- underlying hardware system where VM runs
- Virtual machine manager (VMM) 虚拟机管理器 / hypervisor (hyper-V) 虚拟化监控程序
- creates and runs virtual machines by providing interface that is identical to the host
- (except in the case of paravirtualization 部分虚拟化)
- Guest 客户机
- process provided with virtual copy 虚拟副本 of the host
- usually an operating system
- Host 宿主机
- Single physical machine can run multiple operating systems concurrently 同时, each in its own virtual machine
