计算机系统结构-CS2305
数表示
整数
正/反/补
补:取反+1
(负数比整数多一个)
sign/unsigned
$[x] = x \ge 0 \, ? \, x : (2^{n+1} + x)$
$[x+y] = [x] + [y]$
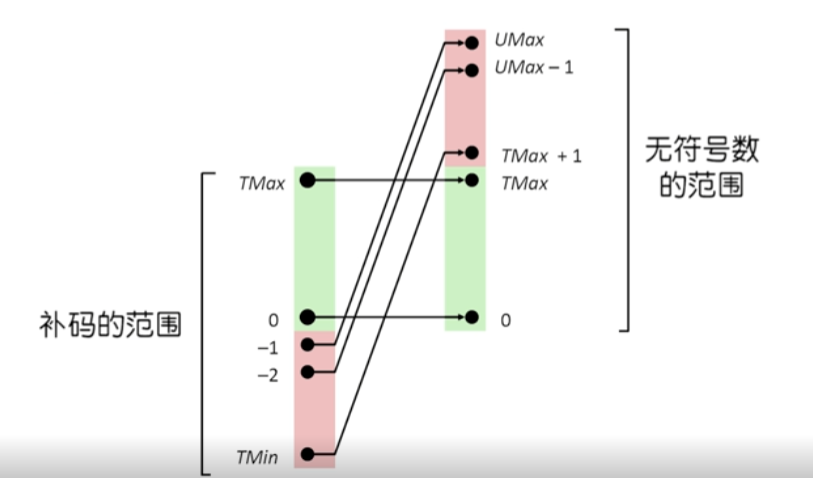
位
&|^~
扩展
0扩展/符号位扩展
截断int i = 32768; // 0x00008000h
short si = (short) i; // 0x8000h
int j = si; // 0xFFFF8000H -32768
左移 sll
- 抛弃最高位
- 可能发生溢出
右移
- 逻辑右移:左补0
srl - 算术右移:左补符号
sra
溢出
- 符号位:{+} + {+} -> {-} ,{-} + {-} -> {+}
- CarryIn[N-1] XOR CarryOut[N-1]
整数乘法
乘一位左移一位
- 模拟手算
不存在==补码乘法==
- 原码乘法器(先转原码,乘算,再转补码)
- Booth算法
- 原理:将乘法转换为对2^n的加法、
C语言:抛弃前w位,保留后w位
- 无论2个w位数字表示无符号数还是补码,截断后得到的w位竭股肱都是在正确的
- 无符号乘法和有符号乘法共用乘法部件
移位等效:$u << k$ 总等效于 $u \times 2^k$
- 对无符号和有符号数都有效
- 速度快,编译器会自动优化
溢出防范
int x,y;
x = 65535; // 0000 FFFFH
y = x * x; // FFFE 0001H -> -131071
int ele_cnt = 2^20 + 1, ele_size = 4096 = 2^12; |
小数
浮点数的表示
S + E + M (规格化位0.1xxxx)
- $N = (-1)^S \times M \times R^E$
- S 符号位 - 正负
- M 尾数 - 纯小数
- E 阶数 (浮点数的指数) 是整数
- 计算机二进制取基R = 2
13.125 = 0.1101001 * 2^100阶码多 -> 范围大,尾数多 -> 精度高
16位浮点
- 4位阶码+12位尾数含符号位
IEEE754浮点数
$(-1)^s \times 1.m \times 2^{e-127}$
规格化为1.xxxx,把1缺省存储,尾数范围加一位
float32: 约7位decimal小数(24尾数位)
$2\times 10^{-38} < N < 2.0 \times 10^{38}$
double64: 约15位decimal小数(53尾数位)
$2\times 10^{-308} < N < 2.0 \times 10^{308}$
先比较符号位,负数符号位是1,之后可以和unsigned integer一样比较大小
计算:
- 对阶
- 尾数相加
- 规格化检查
- 舍入
- 溢出检测
浮点运算不是精确的
和大很多的数相加的时候会丢失比较小的数(可表示尾数的位数有限)
(对阶时阶码差的绝对值>25)
舍入
最近
判断后面的位数构成的数是否>100…0 ? <100.00
如果等于100...0,**令最后一位为偶数**
正向
->
负向
<-
截断
朝0
double/float -> int
可能溢出
发生0方向舍入
(int)3.3/1.1 = 2
不要用\==判断,而是fabs(3.0-a)>0.00001
数据存储
大/小数端
大:最低字节存储在高地址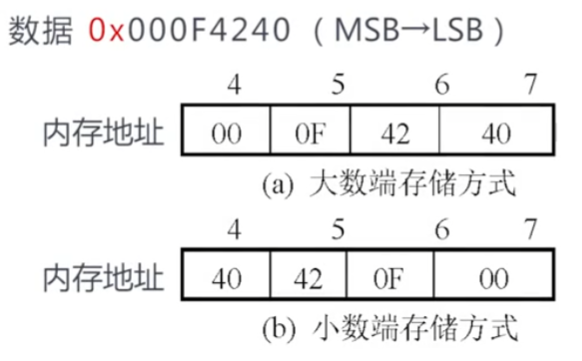
*这种存储是以字节单位的
字对齐
对齐/非对齐
MIPS基础
Mips指令结构
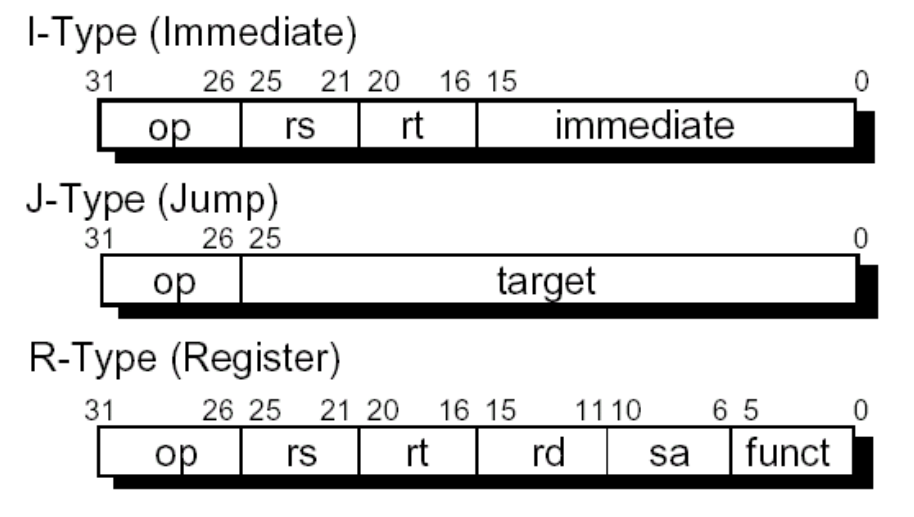
结构
注释
#注释.*
.data:
.word:
.text:
寄存器
0 $zero 常量0 (The Constant Value 0)
1 $at 汇编器临时变量 [a]temp
2-3 $v0-$v1 函数返回结果、表达式值 value returned [0-1]
4-7 $a0-$a3 函数调用时传递的参数 arguments [0-3]
8-15 $t0-$t7 临时变量 Temporaries [0-9]
16-23* $s0-$s7 需要保存的临时变量 [Save]Temp [0-7]
24-25 $t8-$t9 临时变量 Temporaries
26-27 $k0-$k1 为操作系统内核保留 [Kernel]Temp [0-1]
28 $gp 全局指针 Global Pointer
29 $sp 栈指针 Stack Pointer
30* $fp 结构指针/桢指针 Frame Pointer
31* $ra 返回地址 Return Address
# 常常用来存储code段指令地址以供函数等返回
寄存器使用规范
被调用函数应该保存的:
GP SP FP(指针28-30,RA不保存)
S0-S7 需要保存的临时变量由主调函数保存的:
a1-a3 参数寄存器 (arguments)
ra
t0-t9 临时寄存器
基础指令
不含立即数(R Type)
{operation} {value}, {operand1}, {operand2(if exists)}
含立即数(I Type)
{operation} {value}, (%immediate){operand}
状态转移 (J Type)
{operation} {target}
赋取值
(I - Type)
lw — load word
sw — save word
算术
加
add
addi —int
addu —unsigned int
addui —unsigned + immediate
减
sub, subu
与/或/或非
and, andi
or, ori
nor
左/右移 (R)
sll —shift left logic
srl
eg. sll $t2, $s0, 8 (逻辑移位,空出位置清零)
Go To
bne — go to if not equal
beq — go to if equal
J %PC’ or {Label}
JR {$x}
JAL %PC’ or {Label}
转移并链接 Jump and link
将下一条指令的地址,即PC+4保存在寄存器 $ra 中,从而当过程返回时可以链接到当前指令的下一条指令。
伪指令
* only the assembler gets to use $at
subu {}, {}, {}
mov {dst},{src}
la dst,label (load address)
li dst, imm (load immediate)
堆栈
利用$SP完成
addi $sp, $sp, -4 # 移动指针 (push s0) |
int f; |
处理器设计
设计处理器的五个步骤
- 分析指令系统,得出对数据通路的需求
- 选择数据通路上合适的组件
- 连接组件构成数据通路
- 分析每一条指令的实现,以确定控制信号
- 集成控制信号,完成控制逻辑
单周期处理器
基本元件
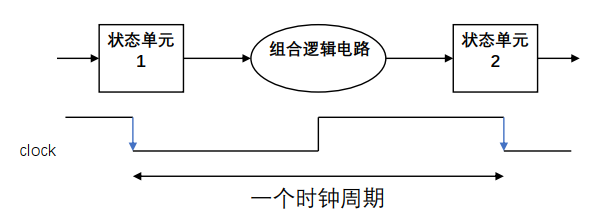
读状态单元的内容
-> 通过组合逻辑电路实现指令的功能
-> 将结果写入一个或多个状态单元
每周期更新一次状态单元,是否更新需要显式信号
寄存器、存储器在时钟边沿来到、写允许信号有效时更新状态(下一个周期写入)
状态单元:寄存器文件
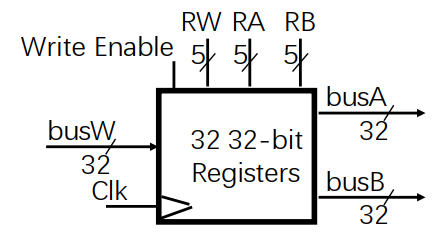
- CLK(时钟输入):时钟边沿触发状态转换
32个寄存器
- 两个32位输出: busA 、 busB
- 一个32位输入: busW
寄存器选通
- RA(5位):选通RA指定的寄存器
- RB (5位):选通RB指定的寄存器
- 读操作,看做一个组合电路模块的实现
- RA 、 RB 有效 => busA 、 busB 有效
- RW(5位): 选通Rw指定的寄存器
- 写操作: CLK边沿触发
- 当Write Enable 为1时,将busW 端口上的数据写入Rw指定的寄存器
状态单元:存储器
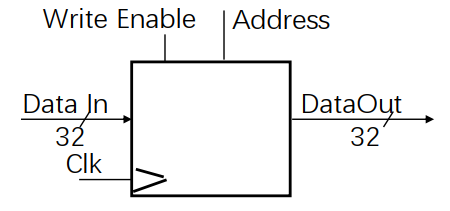
- 时钟输入 (CLK)
- 改变存储器状态需要时钟边沿触发
- 存储器总线
- 32位数据输入总线: Data In
- 32位数据输出总线: Data Out
- 读写操作
- 读操作,看做一个组合电路模块的实现
- 一定时间内完成从“地址信号有效” (Address) =>“数据输出” Data Out
- 写操作:时序电路
- CLK边沿触发
- Write Enable = 1: 将Data In的输入写入Address选中的那个字
数据通路上的其它单元
组合逻辑单元
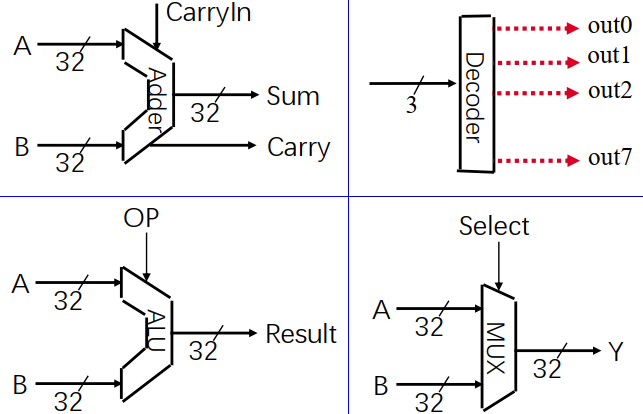
- 32位加法器
- 3-8译码器
- ALU
- 多路选择器 MUX
数据通路连接
取指令
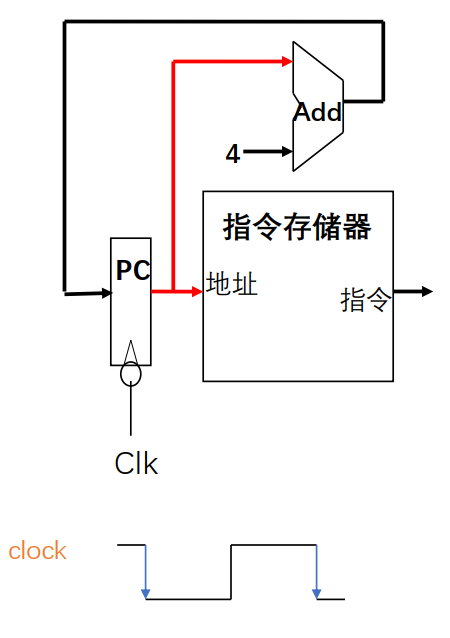
- 收到CLK信号
- ->把PC值发送给指令存储器
- ->把PC值发送给加法器,加法器将发出PC+4信号
这个信号可能接入其它组件,最后输入寄存器的并不一定是PC+4
指令译码
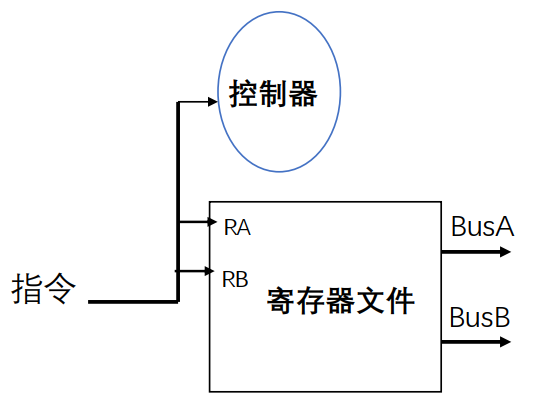
- 读寄存器
- 指令中的寄存器地址连接到RA和RB
- 从寄存器文件读,输出到BusA和BusB
控制信号
| 信号名称 | 无效(=0)时的作用 | 有效(=1)时的作用 |
|---|---|---|
| RegDst | 写寄存器在寄存器文件中的目标寄存器的编号来自于rt字段 | 写寄存器在寄存器文件中的目标寄存器的编号来自于rd字段 |
| RegWrite | 无 | 写数据输入的值,写入到目标寄存器编号(rt或者rd)选择的通用寄存器 |
| ALUSrc | ALU的第二个操作数来自于寄存器 | ALU的第二个操作数来自于立即数 |
| MemWrite | 无 | 将地址输入指定位置的存储器内容替换为写数据输入的值 |
| MemtoReg | 送往寄存器文件写数据输入的值来自于ALU的输出 | 送往寄存器文件写数据输入的值来自于数据存储器的输出 |
| ExtOP | 16位立即数零扩展到32位 | 16位立即数带符号扩展到32位 |
| Branch | 选择PC+4作为PC输入端 | 是一条应该转移的分支指令 |
| Jump | 不选择Jump目标地址,而是选择PC+4或者条件转移目标地址,作为PC输入端 | 是一条应该转移的分支指令,选择Jump目标地址作为PC输入端 |
相关性与冒险
冒险:
结构冒险
硬件资源相关性
数据冒险
数据依赖性
控制冒险
转移指令引起,需要根据指令的结果决定下一步
结构冒险
指令和数据
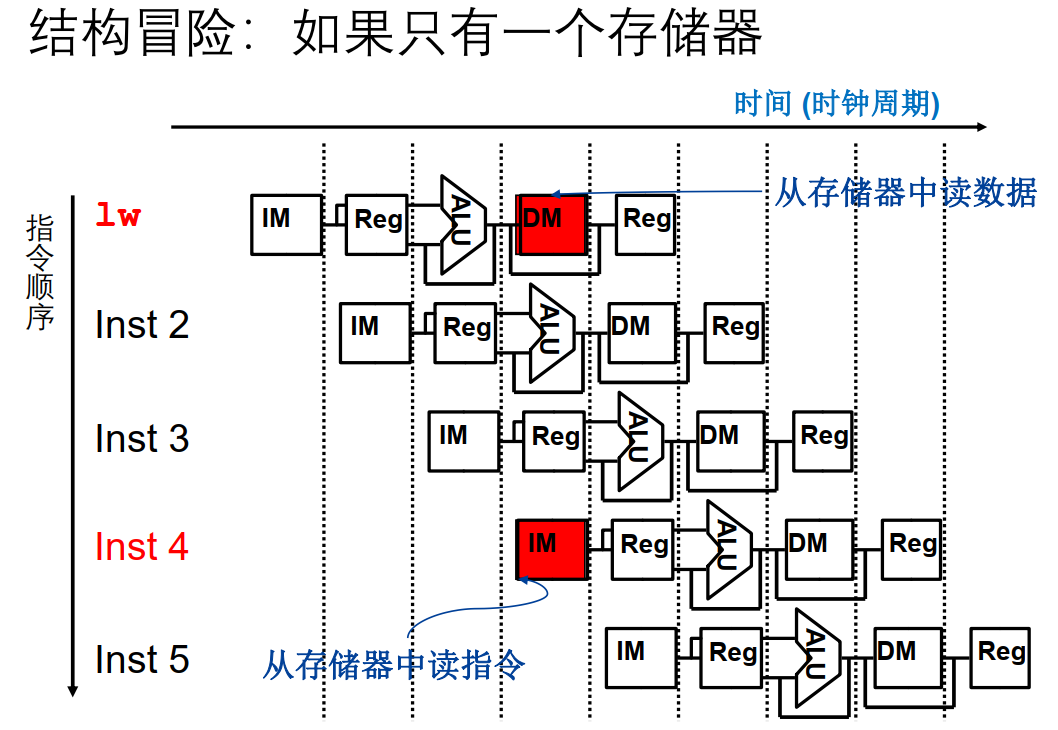
方案1:插入空指令
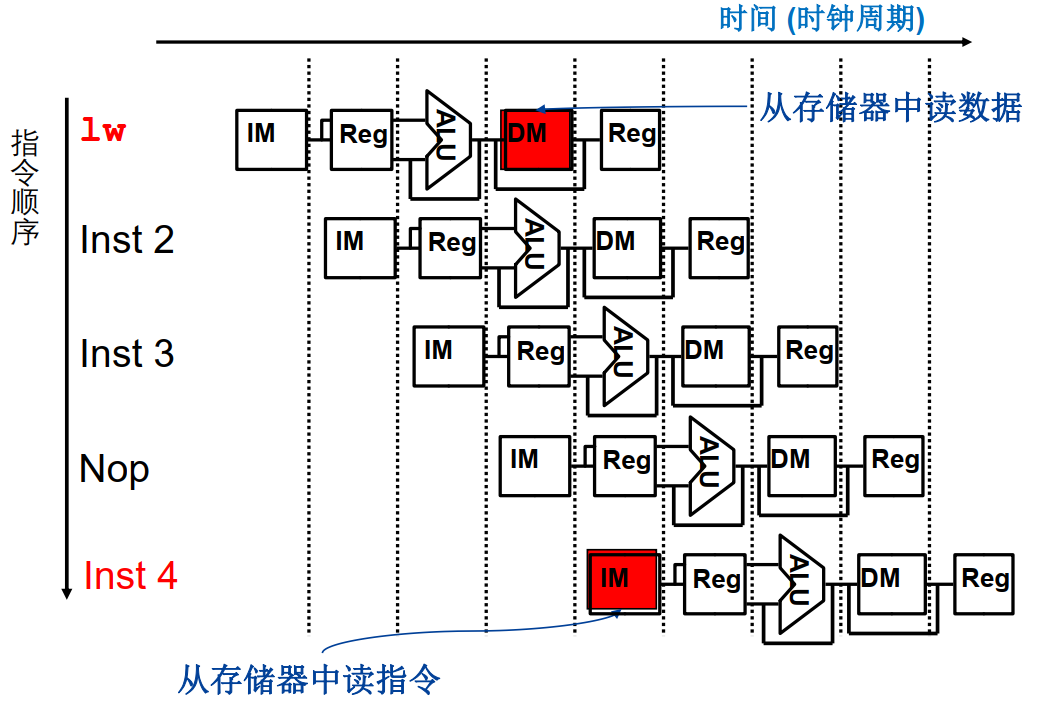
方案2:指令存储器和数据存储器相互独立
寄存器文件的读写
设置相互独立的读写口,写在前半周期完成,读在后半周期完成
数据冒险
写后读数据冒险
需要修改目标寄存器内容,尚未写入,而新指令需要读取该寄存器
“读存储器-使用 ” 冒险
目标寄存器需要读入内容,尚未写入,而新指令需要读取该寄存器
软件解决:插入空指令
硬件解决:
流水线停顿
前向传递(forwarding)
不等写回寄存器,就将产生的结果直接传送到当前周期需要结果的功能单元 (例如: ALU)的输入端
不能解决读存储器冒险
需要一个周期停顿(等待读取指令完成DM)
控制冒险
流水线遇到分支(转移)指令和其它改变PC值的指令时,会引起流水线的停顿
例如
无条件转移(j, jal, jr) 和 条件转移 (beq, bne)
Jump: flush
清空IF/ID段中的指令
转移控制槽(编译器和处理器的约定)
-> 解决方案:转移预测
静态:程序执行前预测
动态:程序执行时预测
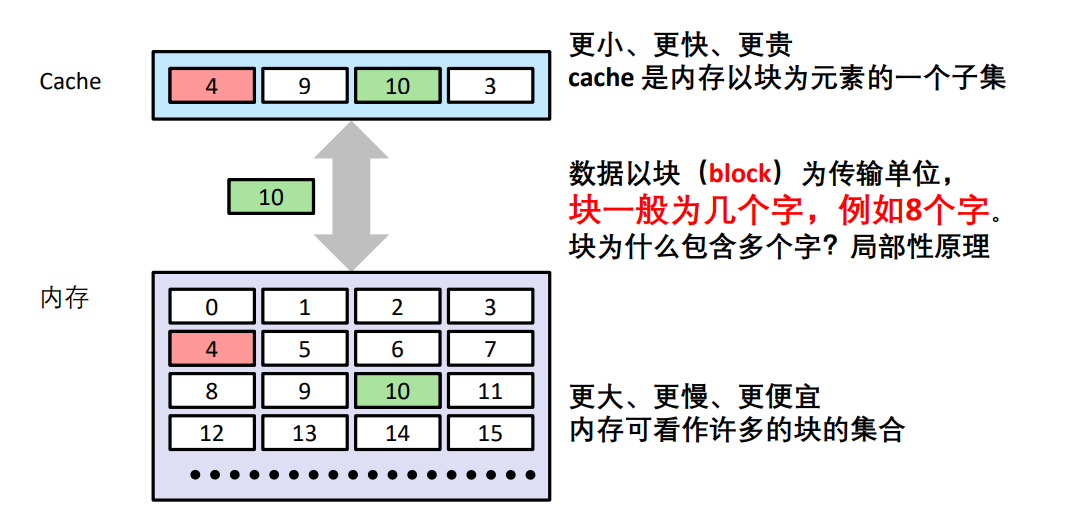
高速缓存
CPU register -> [SRAM -> DRAM] ==内存== -> [SSD -> 磁盘/光盘] ==外存==
- cache 存储器( Cache memories )
- 在处理器附近增加一个小容量快速存储器(cache)
- 基于SRAM,由硬件自动管理
- cache基本思想:
- 频繁访问的数据块存储在cache中
- CPU 首先在cache中查找想访问的数据,而不是直接访问主存
- 我们希望被访问数据存放在cache中

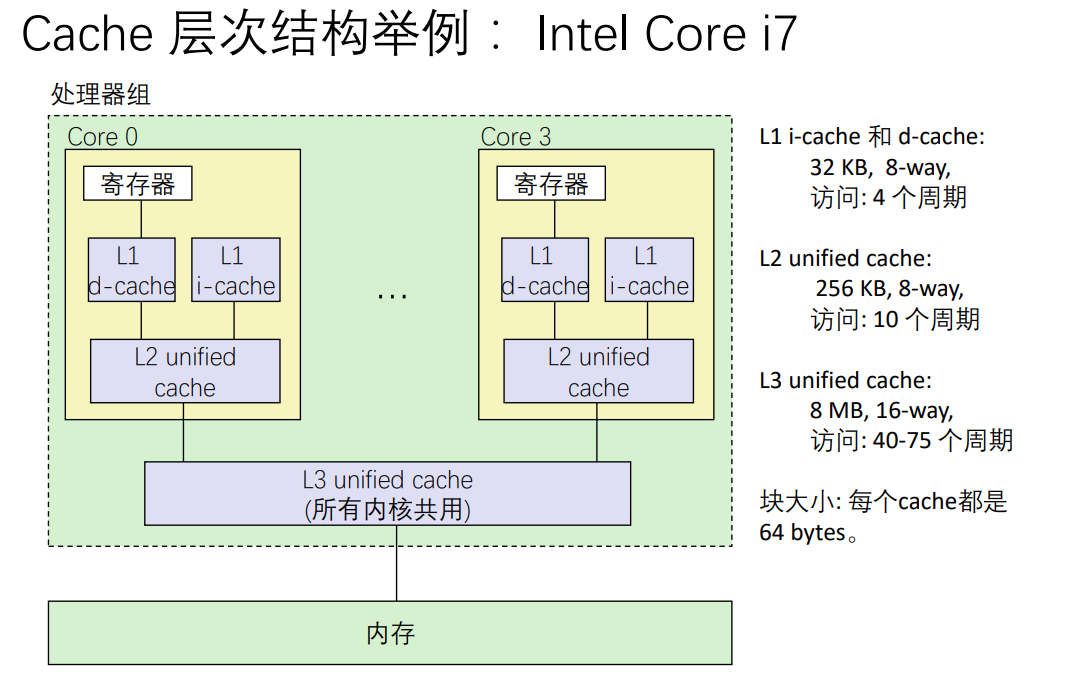
局部性原理 locality
- 时间局部性
- 最近访问的项目,在不久的将来将会被访问
- 空间局部性
- 与当前项目地址邻近的项目很可能会同时被访问
基本概念
- 块
- 一般为多个字
- (空间局部性)
命中Hit / 失效Miss
- 需要访问的元素所在块是否被存储在cache中
- Miss:
- 从内存中取出该块
- 放置在cache中
- 放置策略
- 替换策略
- 命中率h
- 平均访问时间
- $t_a=ht_c+(1-h)t_m$
关键问题
- 如何判断数据是否在cache中
数据查找 Data Identification - 如何查找数据位置
地址映射 Address Mapping - cache满后如何处理
替换策略 Placement Policy - 保持cache和memory一致性
写入策略 Write Policy
- 如何判断数据是否在cache中
地址映射
直接 (direct mapped)
| Main address | Tag Bits | Index Bits | Offset Bits |
|---|---|---|---|
| / | 区编号(upper) | 区索引 | 块内偏移 |
数据块大小 Block_Size = 2^Offset_Bits
缓存 Cache_Size = Block_Size * Cache_Entries ( = 2^Index_Bits)
* Valid Bit
-> each tag entry has an indicator to show if it’s valid
==主存分区 (区号tag bits),每一个区索引(index bits)对应缓存块的一行,比较tag确认Hit/Miss==
优点
- 地址变换速度快,一对一映射
- 替换算法简单、容易实现
缺点
- 容易冲突,cache利用率低
- 命中率低
全相联 (fully-associated)
组相联 (set-associated)
主存地址 = Tag + 组 + 块内偏移
-》
Cache地址 = 路 + 组 + 块内偏移
直接-》组相联-》全相连
每组可存一个tag / 每组可以存多个tag(数量=路数) / 共一组,可以存很多的tag(tag是全局的)
写策略
Cache命中的基础上
- 写直达法 Write-through
- 直接向内存中写入数据
- 写入cache的同时写入memory
- 写回法 Write-back
- 推迟对内存的写入直到数据所在缓存的行被替换
- 添加dirty bit(页面重写标志位)
- 只写入cache,被替换时修改
- 写直达法 Write-through
Cahce失效的基础上
- 按写分配 Write-allocate
- cache读入失效行
- 与write-back搭配
- 不按写分配
- 直接向内存写入,不读入缓存
- 与write-through搭配
- 按写分配 Write-allocate
策略总结
- 写直达+不按写分配法 (Write-through + No-write-allocate)
- 安全性更高
- 写回法+按写分配法 (Write-back + Write-allocate)
- 速度更快
- 写直达+不按写分配法 (Write-through + No-write-allocate)
替换策略
(在现代操作系统讲过)
- 随机替换
- 先进先出FIFO
- 近期最少使用LRU
- 伪LRU
- Clock
- NMRU
Cache友好的代码
eg. C语言的数组元素是以行为主顺序分配的,同一行的元素被分配在连续的内存空间中 -> 利用了空间局部性