现代操作系统CS2310 速效版
操作系统基础
- 关于抽象abstaction
- (计算机组成的重要概念)
- 层次化抽象
- 将系统划分成多个层次,每个层次都对下层屏蔽了具体实现细节,只向上层提供了一组简单的接口,从而简化了系统的设计和维护。
- 对于计算机系统结构,可以抽象为硬件层、操作系统层、系统程序层、应用程序层、用户层。每个层次都对下层屏蔽了具体实现细节,只提供了一组简单的接口。
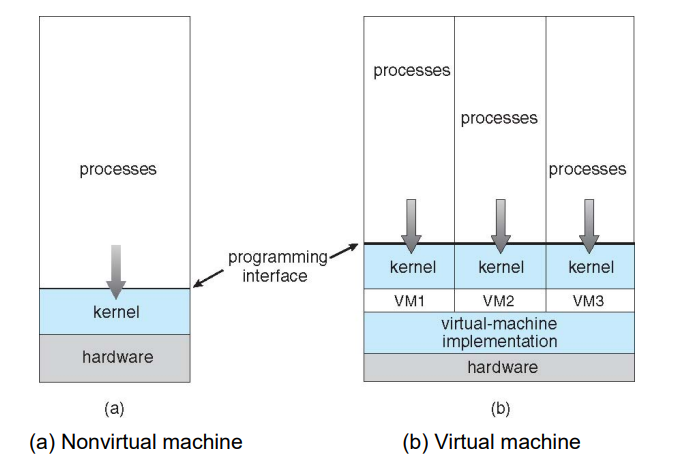
- 虚拟机 (Vitural machines)
- ==virtualization layer==
- vitural cpu & memory & devices

- vitural cpu & memory & devices
- ==virtualization layer==
什么是计算机操作系统 (Operating system / OS) ?
- 一种介于计算机用户与计算机应用间的“程序”
- 一个系统资源的分配者、其它程序的控制者
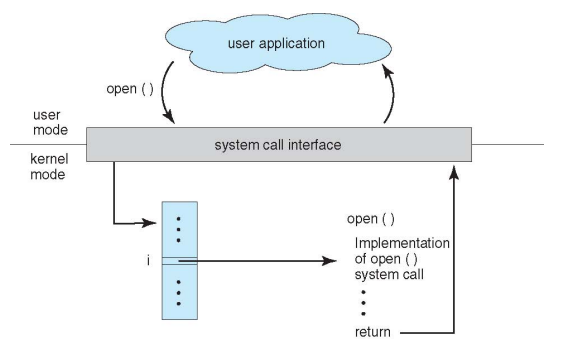
系统调用 (System Call)
- OS提供的可编程接口
- 比如 fork() exit() wait() (unix) 等
- 比起使用系统调用,OS也向各类服务提供应用程序接口 ( Application program interface / Api) -> 可以视为一种对系统调用的封装和抽象
- 简单,易移植
- eg. Win32 API, POSIX API(UNIX, Linux, Mac OS), Java API(JVM)
- OS提供的可编程接口
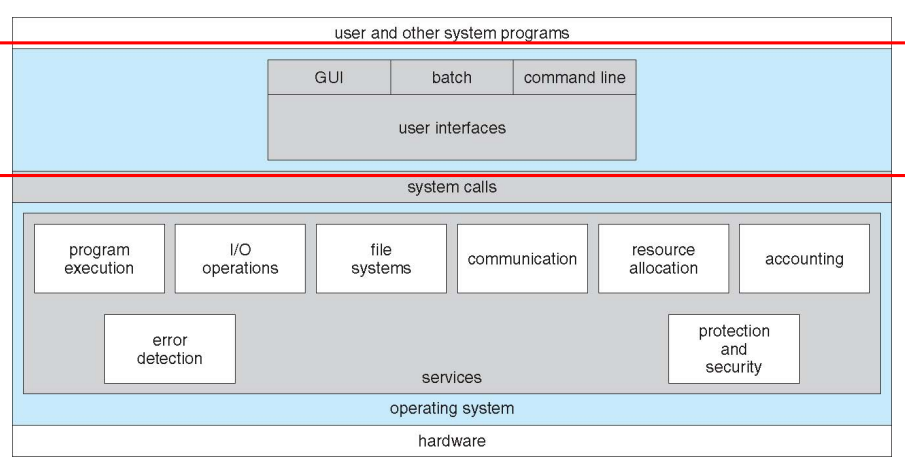
提供服务
- GUI
- program execution
- IO operations
- File-system manipulation
- communications
- error detection
- resource allocation
- accouting
- protection & security
Outline
- 进程管理
- 进程/线程/同步/死锁
- 内存管理
- 内存/虚拟内存
- 存储管理
- 文件系统/大容量存储结构/IO系统
- 分布式系统结构
- 进程管理
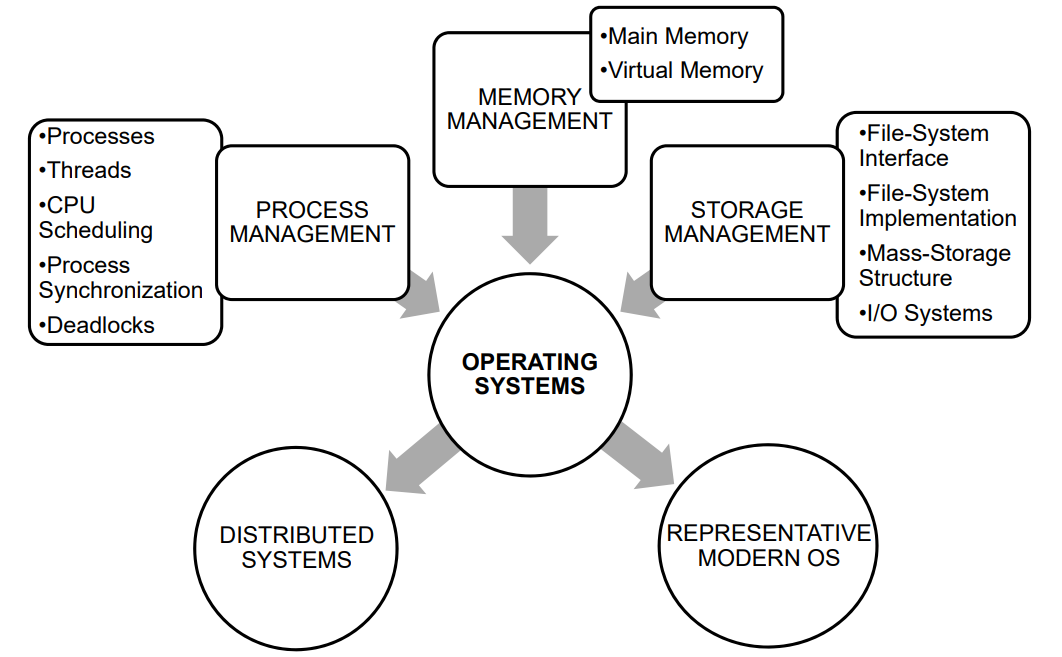
进/线程调度
并发 & 并行
- 并发 Concurrency
- 时分复用:多个任务在同一时段内共享资源,交替运行

- 并行 Parallelism (multi-core system)
- 多个任务在(通过多个处理单元)同一时刻同时执行,互相独立
- 多个任务在(通过多个处理单元)同一时刻同时执行,互相独立
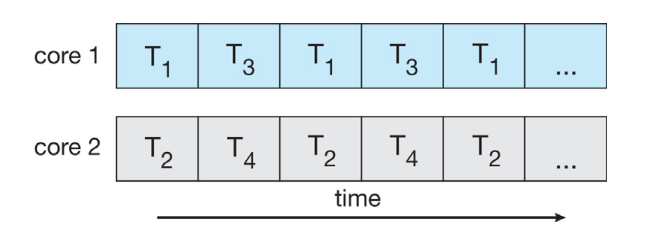
进程 & 线程
| 进程 process | 线程 threads |
|---|---|
| 独立存在 | 作为进程子集存在 |
| 携带更多状态信息 | 共享内存.系统资源 |
| 独立地址空间 | 共享地址空间 |
| 仅通过IPC通信交互 | 更多方式 |
| 上下文切换比较慢 | 同进程内切换速度很快 |
- 线程是进程内的执行单元,不能独立于进程存在,而只能在进程中产生。
- 每个线程都共享了进程的地址空间、文件描述符表和其他系统资源。
- 可以认为正因为线程之间共享了部分资源,如代码段、数据段和文件描述符表等,因此在线程之间进行切换时,不需要像进程切换那样复制和恢复整个地址空间,这使得线程切换速度更快。
- 同时,由于线程之间共享了相同的地址空间,因此线程之间的通信更加容易和高效。线程可以直接访问同一进程内的共享内存,无需通过进程间通信(IPC)的方式进行数据传递,这减少了通信的开销和复杂性。
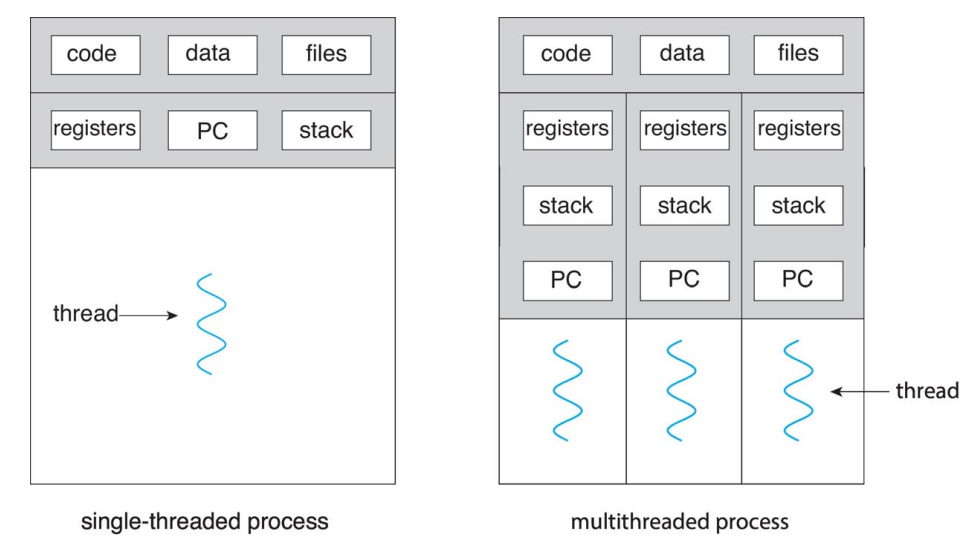
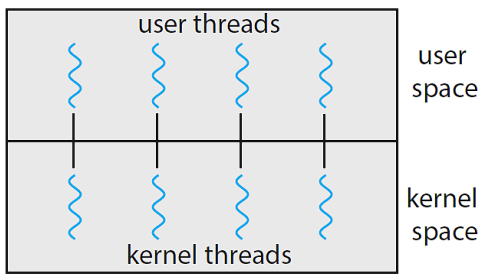
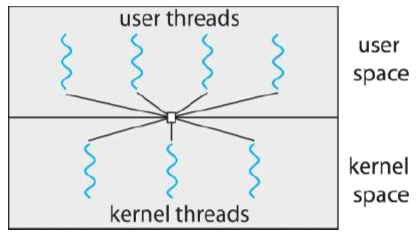
用户线程 (user threads) & 核线程 (kernel threads)
- Many-to-one
多个用户线程对核隐藏,映射到一个内核级线程上,由内核级线程来执行
单个用户线程出现问题会导致同组线程都出问题;不能并行运行
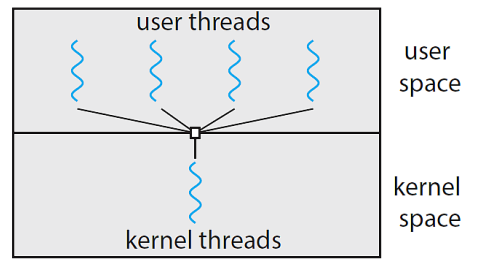
- One-to-one
高并行支持
创建kernel thread有开销
Linux, windows NT/XP/2000, Solaris 9+
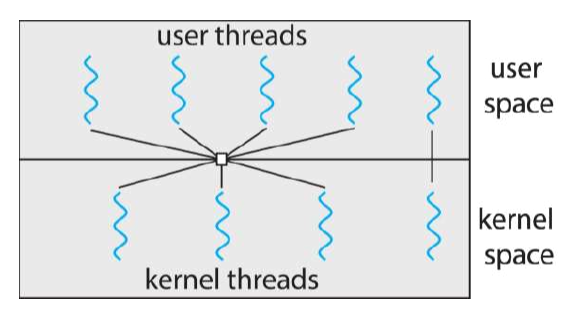
- Many-to-many
操作系统重构一定数量核线程
Windows NT with the ThreadFiber package - Two-level
在Many-to-many的基础上运行用户线程与核线程1对1绑定
进程 process
进程 process ( = job 作业)
- program becomes process when the exe file is loaded into memory
- 开始运行的程序被载入内存,成为进程(此处的“内存”、之后的“组分”与虚拟内存有关)
- 1 program can be several processes
- 一个程序可以产生多个进程
- program becomes process when the exe file is loaded into memory
一个进程的组成部分 conposition:
- 栈 stack
- …
- 堆 heap
- memroy dynamically allocated during run time
- 数据 data
- 文本 text
- programme code
PCB (Process control block)
- state
- num
- counter
- registers
- mem limits
- list of open files
- …
—> 包含进程的状态;控制;上下文切换;通信和同步;优先级管理信息
进程的状态 process state
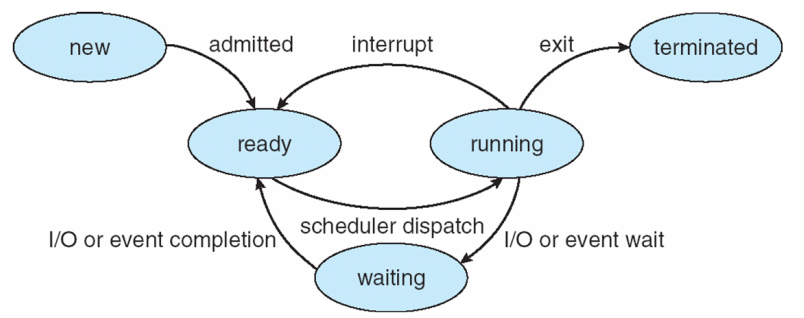
- 一个新的进程的一生:
- 创建 (new)
- 就绪 (ready)
- 进程就绪,等待处理器分配资源
- 比如CPU正在忙着处理别的进程,可能新的进程就要等待
- 运行 (run)
- 执行指令
- 等待 (wait)
- 进程未就绪,等待事件的发生或完成
- 比如等待键盘输入字符
- 终止 (terminated)
- CPU的进程切换过程
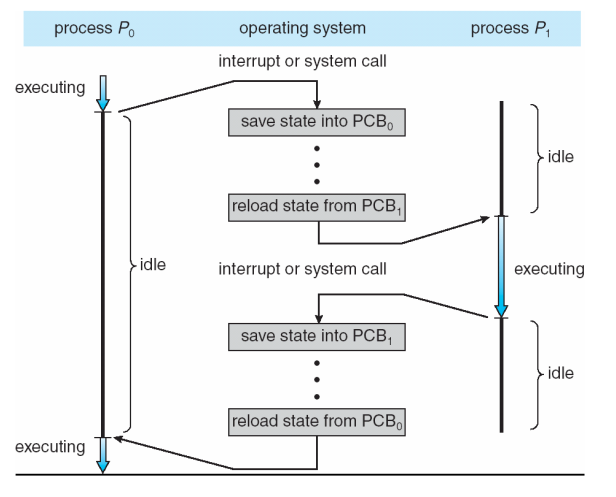
- 保存当前进程的上下文(->PCB0)
- 切换到新进程的上下文(<-PCB1)
- …更新控制信息,开始执行新进程
- 结束执行新进程
- 保存新进程的上下文(->PCB1)
- 切换到原进程的上下文(<-PCB0)
- …
CPU调度 cpu scheduling
抢占 preemptive 和 非抢占 nonpreemptive
- 一个处于Run状态的进程是否可根据调度规则在运行过程中被其它进程中断?
- 能 -> 抢占式:允许中断
- 不能 -> 非抢占式:除非进程结束或者进入等待状态,即释放CPU资源,不允许另一个进程获取其CPU资源
什么是CPU调度
在进程的状态发生以下变化时,CPU可能作“调度”决策
- run -> wait
- run -> ready
- wait -> ready (I/O完成等event发生,等待资源分配)
- terminates
在1.4时做决策 -> 非抢占 (处理进程的等待和结束)
在2.3时做决策 -> 抢占 (处理新的ready进程)
调度器 Dispatcher
控制CPU
- 切换上下文
- 切换进程
- 切换用户/管理员权限
- 用户程序重启
调度延迟 Dispatch latency
time it takes for the dispatcher to stop one process and start another running.
调度算法
均为人为定义,可能会有版本差别。
可以将一切调度理解为队列的设计、出入队规则的设计。
一般不标注可抢占时,认为不可抢占。
先有四种基础决策。
FCFS (First-Come, First-Served)
- Convoy effect - short process behind long process
- 非常基础和朴素的安排方法
- 短进程不友好

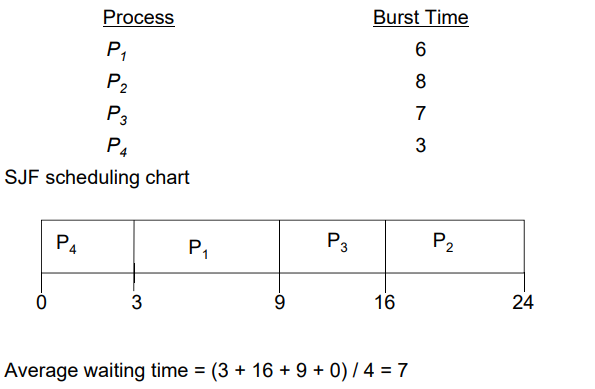
SJF (P/NP)
Shortest-Job-First
- 先处理(预估的)总耗时最短的工作
- SJF(P)
- -> 先处理(预估的)剩余耗时最短的工作
- 小心地处理新进程和被抢占的进程的顺序
- SJF(P)
- 理论最优解
- 事实上,难点在于很难预测到底耗时多久( -> 预测方案)
会导致饥饿
- 等电梯。你住在高楼层。电梯总优先服务低楼层的人下楼。
- 低楼层总有人按电梯。
- 你永远等不到电梯。
- 类似地,优先级调度也会导致饥饿。
Example of SJF (NP)
Example of SJF (P)

优先级调度 PS (P/NP)
Priority Scheduling (高度类似SJF,仅更改判断条件)
- 先处理高优先级进程
- 注意同优先级进程的处理方式
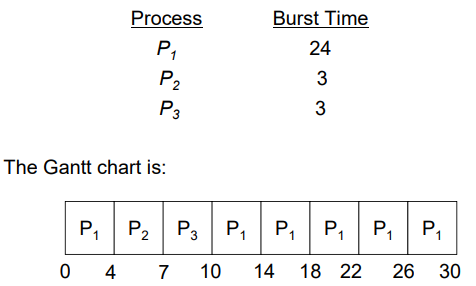
时间片轮转调度 RR (P/NP)
Round-Robin Scheduling
在RR(quatum=q)算法下,每个进程获得一个时间片time slice,长度为q。
关于q
- 当取quatum为一个极大的值,相当于FCFS,对短进程不友好
- 当取quatum为一个极小的值,符合RR的意图,但是会消耗大量时间用于进程切换
- 需要一个较为合适的取值
Example of RR
关于饥饿
- FCFS 不会导致饥饿
- SJF, PS均会导致饥饿
- RR 可以有效避免饥饿
以下为混合决策,更加自定义化,请认真查看题目说明。
多级队列调度 Multilevel Queue Scheduling
multiques, eg. foreground & background
- each queue has own scheduling algo 每个队列都有独立的出队规则
- schedule between queues:
- eg1. fixed prority 规定出队优先级
- serve all from queue1, then 2
- may cause starvation
- eg2. time slice 轮转从两个队列调取进程
- each queue has a time slice
…
- each queue has a time slice
- eg1. fixed prority 规定出队优先级
多级反馈队列 Multilevel Feedback Queue Scheduling
a kind of ↑
- structure:
- queues 多少队列
- each queue’s sche algo 每个队列的出队规则
- method
- when to upgrade/demote jobs 任务的转移规则
- which queue a process will enter when that process needs service 进入时的初始队列
- classic example:
Q1(RR(8))->Q2(RR(16))->Q3(FCFS)
In Q1/Q2, not completed -> degrade and queue
If not used up and not degrade, requeue ( & get a new time slice)
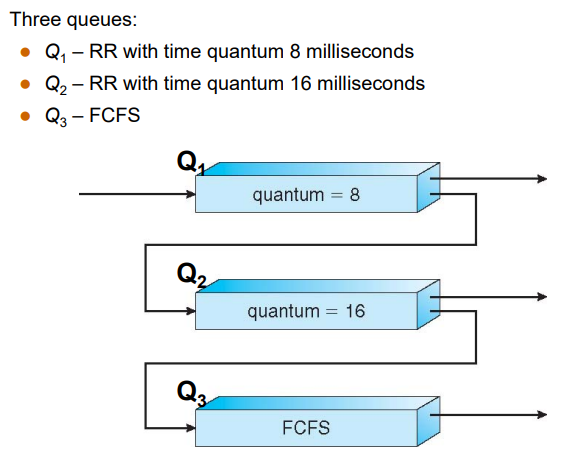
- Example of MFQ

锁管理(进程同步)
进程同步 Process Synchronization
- producer - consumer problem
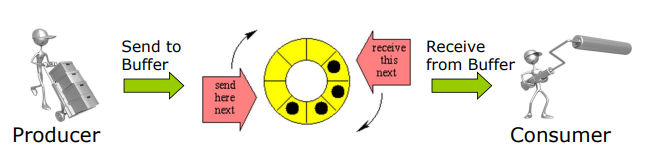
Critical Section Problem
- 临界资源:每个进程的访问互斥
(When one process is in critical section, no other processes may be in its critical section) - find protocol to solve 防止竞争的==协议==
- 临界资源:每个进程的访问互斥
Critical Section
do {
entry section // 资源保护开始
== critical section ==
exit section //资源保护结束
remainder section
} while (TRUE)To solve this
- Mutual Exclusion 互斥
- Progress
- work when OK and don’t postpone indefinitely
- Bounded Waiting 有限等待
- Sequential Access 顺序访问
如何实现同步
原语 / 原子操作 Atomic
Many systems provide hardware support for critical section code
- Some machines provide special atomic hardware instructions (原语)
- Atomic = non-interruptable
Test&Set (TAS)
Either test memory word and set value: TestAndSet ()
Definition (由硬件实现)
boolean TestAndSet (boolean *target)
{
boolean rv = *target;
*target = TRUE;
return rv:
}Example (share bool Lock(False))
Solution:
do {
while ( TestAndSet ( &lock ))
; // do nothing
// critical section
lock = FALSE;
// remainder section
} while (TRUE)
->(Add bounded-waiting) :
每个进程在一段时间内只能获取一定次数的testandset操作资源,如果达到阈值,就等待一定时间后再尝试获取do {
waiting[i] = TRUE;
key = TRUE;
while (waiting[i] && key)
key = TestAndSet(&lock);
waiting[i] = FALSE;
// critical section
j = (i + 1) % n;
while ((j != i) && !waiting[j])
j = (j + 1) % n;
if (j == i)
lock = FALSE;
else
waiting[j] = FALSE;
// remainder section
} while (TRUE);
Swap
swap contents of two memory words: Swap() — 安全地交换两个内存单元内的数据
- Example
do {
key = TRUE;
while ( key == TRUE)
Swap (&lock, &key );
// critical section
lock = FALSE;
// remainder section
} while (TRUE);
Mutex
- 一种轻量级的同步机制
- 实现两种基本操作:lock和unlock。
- 在lock()和unlock()之间的临界区域内同一时间只有一个进程可以访问共享资源,其他进程必须等待锁被释放才能进入临界区域。
|
Samophore
- 一种用于线程同步的机制,可以用于多线程编程中控制访问共享资源。
- 维护一个计数器和等待队列
Semaphore提供了两个主要的操作:wait(等待)和signal(发信号)。Semaphore的值为整数,初始值可以是任意的正整数,表示可用的资源数目。Semaphore的值只能在wait和signal操作中改变,且改变是原子的,所以可以避免竞态条件。
在C语言中,Semaphore是通过系统提供的sem_t类型来表示的。
- wait(等待):当一个线程想要使用Semaphore代表的共享资源时,它需要调用wait操作。
如果Semaphore的值为正数,则该线程可以使用该资源,同时Semaphore的值减1;
如果Semaphore的值为0,则该线程将被阻塞,直到有其他线程释放资源并增加Semaphore的值为止。
int sem_wait(sem_t *sem);
- signal(发信号):当一个线程使用完Semaphore代表的共享资源时,它需要调用signal操作。
这将增加Semaphore的值,并唤醒等待该Semaphore的线程,以便它们可以继续使用资源。
int sem_post(sem_t *sem);
Semaphore还有其他一些操作,例如初始化、销毁等。在使用Semaphore时,需要注意避免死锁等问题,通常需要仔细考虑线程的同步关系,避免资源竞争等问题。
死锁问题 Deadlock
Deadlock Characterization
- Mutual exclusion 资源互斥
only one process at a time can use a resource - Hold and wait
process holding at least one resource is waiting to acquire additional resources held by other processes 享有资源的进程等待其它资源 - No preemption
a resource can be released only voluntarily by the process holding it, after that process has completed its task 不允许抢占其它进程享有的资源 - Circular wait 互相等待形成环
哲学家吃饭都拿左边筷子
- Each process utilizes a resource as follows:
- request
- use
- release
Resource-Allocation Graph algorithm
-> DEADLOCK AVOIDANCE
通过画资源分配图,检查是否存在死锁,以及确定导致死锁的进程和资源,进而解除死锁 (avoidance) ; 也可以用于避免死锁(在分配前检查是否可能导致死锁)
- The graph represents the relationships between resources and processes in the system. 用资源分配图可以表示当前的资源和进程关系
常用于每个资源仅有1instance的情况(多个instance时,环路和死锁未必相关)
V:
- P: P1,P2… (process list)
- R: R1,R2… (resource list)
- E:
- request edges ( process -> resource )
- assignment edges ( resource -> process )
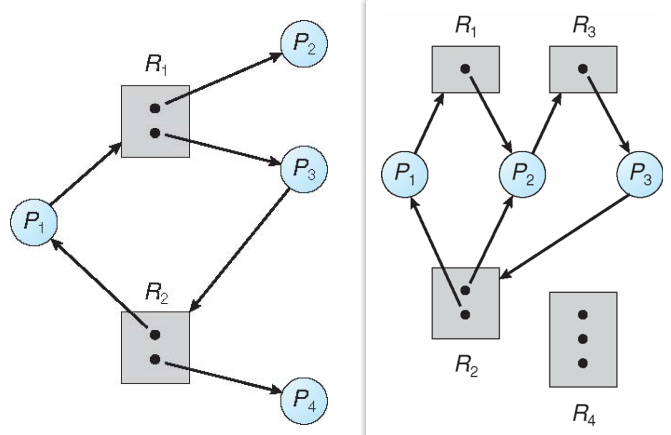
Judge deadlock by graph
- no circle -> no deadlock
- 1 circle ->
- 1 instance / resource type -> deadlock
- ->1 instance / … -> possibility of deadlock
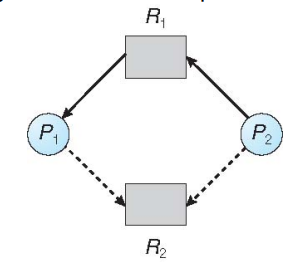
upgraded resource-allocation graph:
- Each process must a priori claim maximum use
- claim edge 有向虚线:进程P可能请求资源R (P->R)
- request edge 实线(P->R)
- assignment edge 实线 (R->P)
In other words, the request can be granted only if converting the request edge to an assignment edge does not result in the formation of a circle in the resource allocation graph.
Safe mode & safe sequence
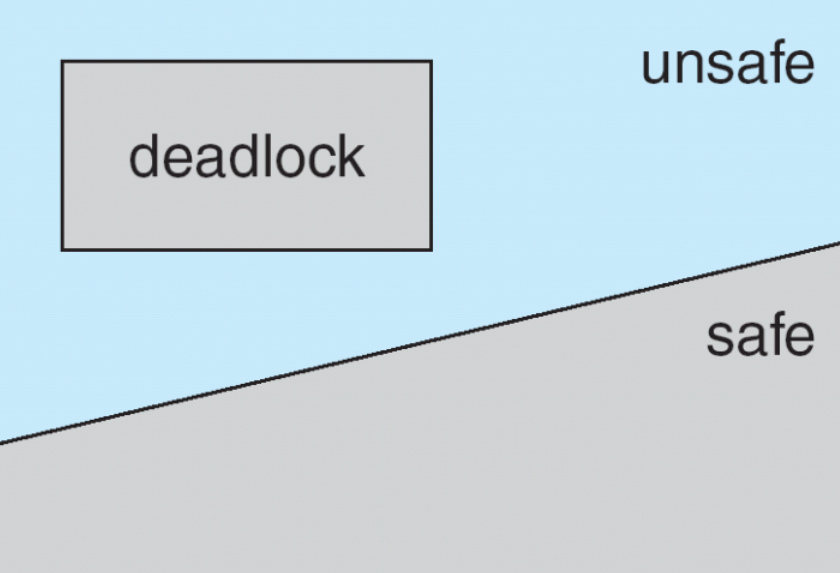
Safe mode
system check if allocation leaves the system in a safe mode to prevent from dead lock 在分配请求发生时检查是否存在安全队列以预防死锁
defination: 系统中每个进程都能够按照它所需的顺序获得资源,执行完自己的任务并释放资源,而不会发生死锁。
- If Pi’s resource needs are not immediately available, then Pi can wait until all Pj have finished
- When all Pj are finished, Pi can obtain needed resources, execute, return allocated resources, and terminate
- When Pi terminates, Pi+1 can obtain its needed resources, and so on
- Otherwise, system is in unsafe state
If a system is in safe state -> no deadlocks
- If a system is in unsafe state -> possibility of deadlock
- starvation 饥饿 …
- Avoidance -> ensure that a system will never enter an unsafe state.
Safe sequence
- eg: find a safe sequence with available resource = 3
| |maximum needs|holds|needs|
|—|—|—|—|
|P0|10|5|5|
|P1|4|2|2|
|P2|9|2|7|
| Avai | P1+ | P1- | P0+ | P0- | P2+ | P2- |
|---|---|---|---|---|---|---|
| 3 | 1 | 5 | 0 | 10 | 3 | 12 |
P1 -> P0 -> P2
每一步寻找可运行的process,完成后释放process和它的所有资源。
如果找不到可运行的process,则出现unsafe state。
The banker’s algorithm
适用于资源有mutiple instances的情况
Defination
n = number of processes
m = number of resources types.Available: Vector of length m.
If available\[j] = k, there are k instances of resource type Rj available- Max: n x m matrix.
If Max\[i,j] = k, then process Pi may request at most k instances of resource type Rj - Allocation: n x m matrix.
If Allocation\[i,j] = k then Pi is currently allocated k instances of Rj Need: n x m matrix.
If Need\[i,j] = k, then Pi may need k more instances of Rj to complete its task Need\[i,j] = Max\[i,j] – Allocation\[i,j]**The algorithm
- work := available, finish[i] = false
- find i that
- finish[i] = false
- need[i] <= work
- if i = -1, go to 4
- work = work + allocation[i], finish[i] = true, go to 2
- if finish[i] = true for all i -> ok, else !ok
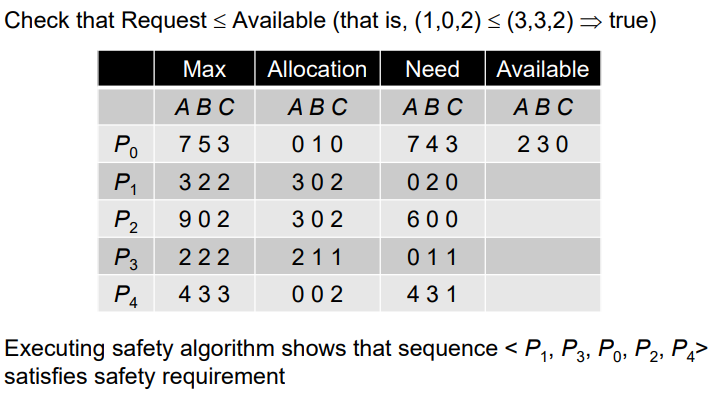
Simulation
+P1->[2,1,0]->-P1->[5,3,2]
+P3->[5,2,1]->-P3->[7,4,3]
+P0->[0,0,0]->-P0->[7,5,3]
+P2->[1,5,3]->-P2->[10,5,5]
+P4->[12,2,4]->-P4->[10,5,7]
Sum up: deadlock handling
PREVENTION
restrain the ways request can be made
shown in [deadlock characterization]
AVOIDANCE
入职检查
Whenever a process requests a resource, the request is granted only if the allocation leaves the system in a safe state.
Help system to add priori info
- Prepare for checking: each process declare max of resources needed
- Dynamically check if there’ll be circular-wait condition
- be defined by available/allocated resourvces, max demands of processes
- safe state checking (bank algo/…) ; circle check
DETECTION
similar to avoidance
RECOVERY
precess termination 进程终结
- abort one or more processes to break the circular wait
- abort all deadlock ones / one at a time until ok
resource preemption 资源抢占
- preempt some resources from one or more of the deadlocked processes
- selecting a victim / rollback 回滚
- ATTENTION: starvation
内存与虚拟内存
MMU (Memory Management Unit)
Hardware component (通常作为一个主板模块与CPU和内存分别相连)
在CPU发生访问需求时,根据内存映射表将CPU中的逻辑内存地址转换成内存中的物理内存地址
每次开机,OS都会从硬盘中读取地址映射表,并将其存储到内存中的特定位置
OS会将这个位置,也就是地址映射表的基地址存储在MMU的 relocation register 重定位寄存器。
Memory Management 内存管理
Allocation Table 内存分配表
由于内存分配表的大小通常比较小,而且遍历它的开销相对较低,所以一般的内存管理方法都使用内存分配表来记录内存的分配情况,使OS可以快速查找到可用的内存块并将其分配给进程。
- 记录内存中分区的起始地址、大小、是否已分配等信息
- 可看作是一个逻辑上的表格,其中每个表项代表一块内存区域
- 由OS在启动时初始化,分配时动态更新
Contiguous memory allocation 连续式内存分配
Defination
- 将可用的内存空间视为连续的地址空间
- 进程被分配的内存空间也必须是连续的物理内存空间。
Multiple-partition allocation 多区分配
- 一种典型的连续式内存分配
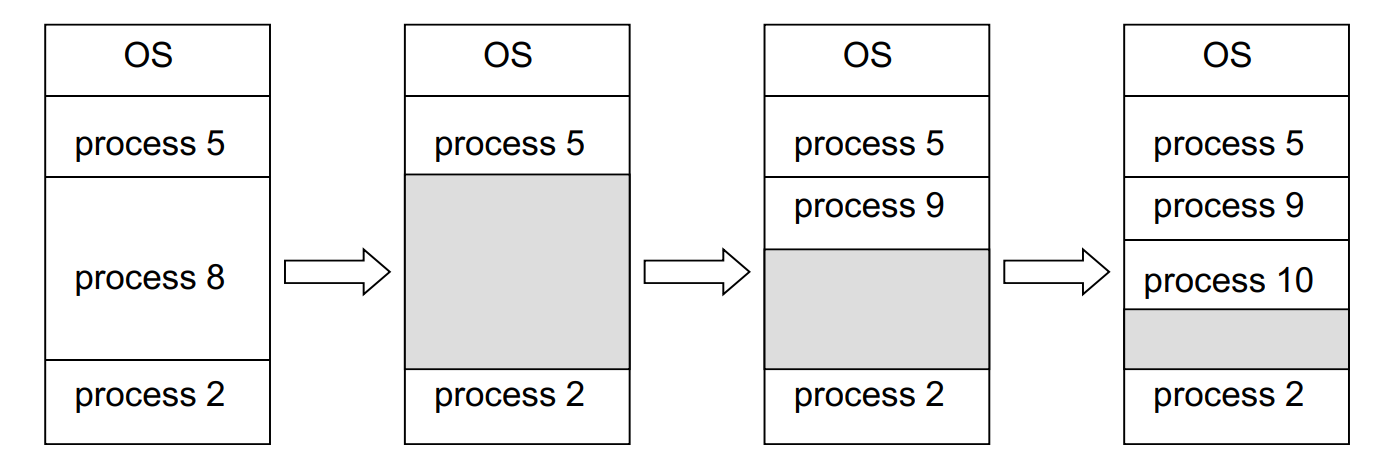
维护内存分配表(包含已分配分区和未分配 (holes) 分区的信息)
Dynamic Storage-Allocation Problem 动态存储分配问题
- First-fit
- Best-fit
- Allocate the smallest hole that is big enough
- must search entire list, unless ordered by size
- Produces the smallest leftover hole
- Worst-fit
- Similarly
First-fit & best-fit better than worst-fit in terms of **speed and storage
- Similarly
分配出去的空间释放后大小未必能够匹配后续需分配的内存大小,导致 内存碎片 (memory fragmentation) 形成。
- 内存碎片 memory fragmentation
- 内存中大量的零散、未被充分利用的小块空闲内存
- 过多碎片可能导致内存空间无法有效利用,也会增加分配内存的开销。
- 外部碎片 (external)
- total memory space exists to satisfy a request, but it is not contiguous
- 内部碎片 (internal)
- allocated memory may be slightly larger than requested memory
- allocating memory internal to a partition, but not being used
-》 使用First fit算法来分配内存时,会发现对于N个块已经被分配,有0.5N个块被浪费在碎片上。其中1/3的碎片可能无法使用,这就是“50%规则”
- 解决方案
- 内存紧缩/重排 compaction/shuffle
- 效率问题
- -> 伙伴系统
- 允许不连续分配 noncontiguous memory allocation
- 内存的分页与分段 paging & segmentation
- 内存紧缩/重排 compaction/shuffle
Buddy System 伙伴系统*
- 将内存分成大小相等的块,每个块都有一个大小的指数级别,例如2的幂次方
- 当分配内存时,伙伴系统会按照2的幂次方去寻找最合适的可用块
- 如果找到一个较大的块,它就会被拆分成两个较小的块,并将它们标记为伙伴块
- 当释放内存时,伙伴系统会将相邻的伙伴块合并成一个更大的块=
- 可以尽量减少传统连续分配模式产生的内存碎片
- 使用比较复杂的数据结构管理伙伴关系和未分配内存
- Linux
Non-contiguous memory allocation 非连续式内存分配
- allow noncontiguous physical address space
Paging 内存分页
Defination
- FRAMES 框 -> 物理内存切块
- divide physical memory into fix-sized blocks
- size is power of 2, 512b - 16Mb
- keep track of all free frames
- divide physical memory into fix-sized blocks
- PAGES 页 -> 逻辑内存切块
- divide logical memory into same sized blocks
- 运行方式
- to run a program of N pages -> find N free frames
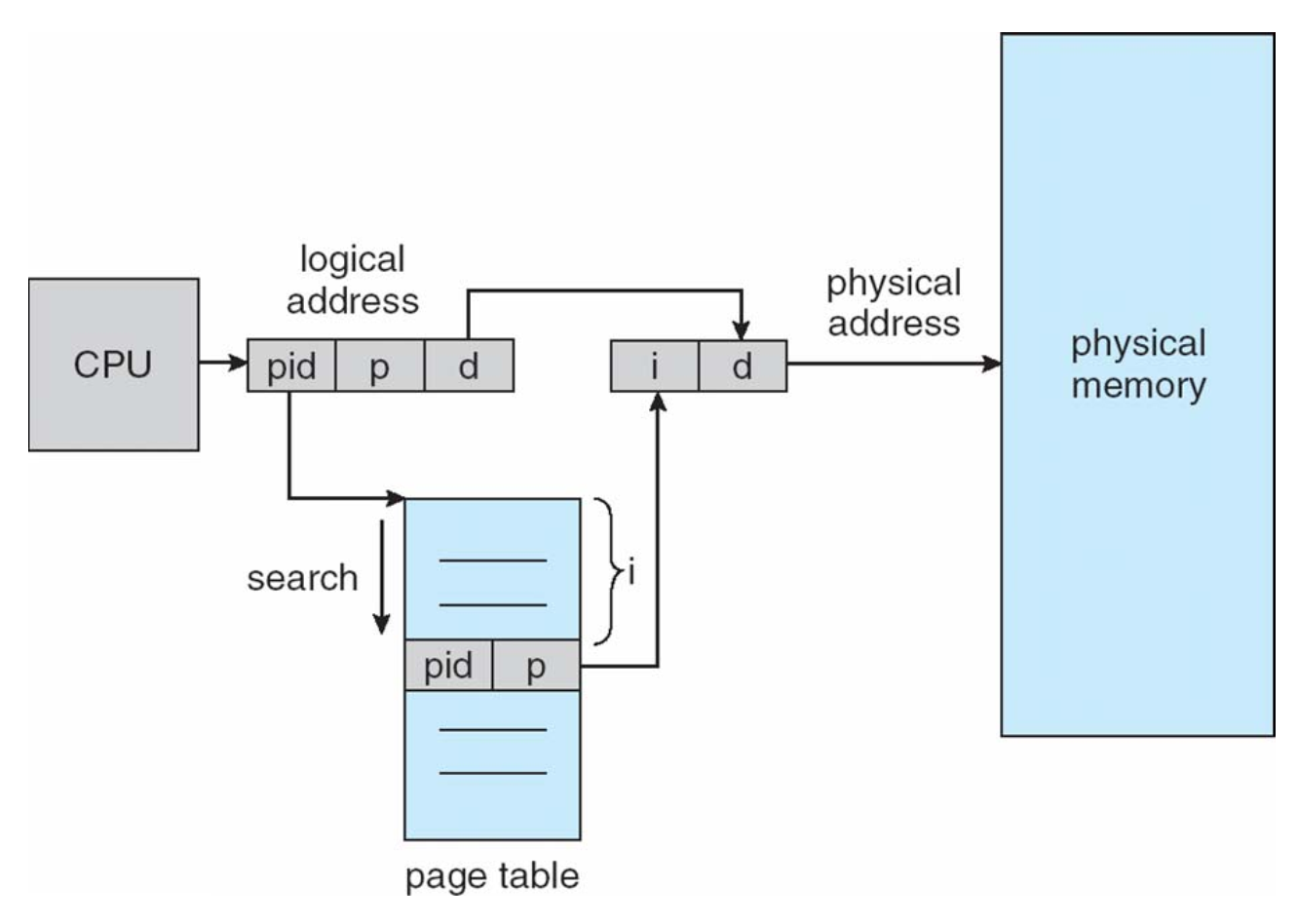
- PAGE TABLE 页表
- translate addresses (page id -> frame id)
- translate addresses (page id -> frame id)
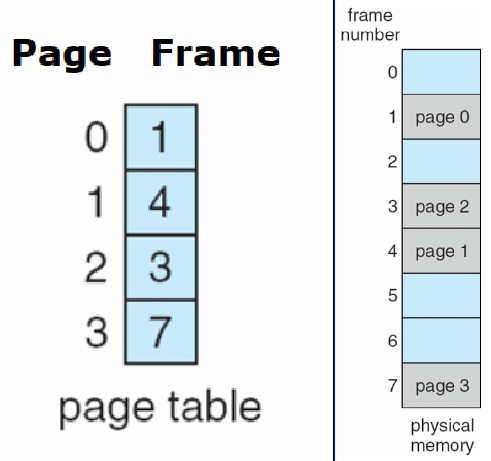
(still have internal fragmentation)
Implementation
Define a logical address as \
- divided by CPU
- page number (p)
- the page’s index in page tables
- page offset (d)
- mapping to offset within that page (frame)
Keep a page table
- PTBR: Page-table base register in CPU
- records the address of the table
- PTLR: Page-table length register in CPU
- indicates the length of the table
- PTBR: Page-table base register in CPU
Obviously, every data/instruction access requires 2 memory accesses (access the table and allocate the unit according to the table)
- Add a TLB to accelerate
- translation lookaside buffer
- record recent accessed table item
- HIT
- fast access
- MISS 内存缺页
- load to TLB, try to hit next time
- EAT (Effective Access Time)
- Associative Lookup = ε time / unit
- Hi ration = α
- EAT = (1 + ε) α + (2 + ε)(1 – α)
TLB scheme
- FIFO
- First-In, First-Out
- 记录页表项进入TLB的时间戳
- 将最早进入TLB的页面替换出去
- LRU
- Least Recently Used
- 记录页表项在TLB中最后一次被访问的时间戳
- 将访问时间最早的页表项替换出去
Second-chance page replacement algorithm
- 给页表项附加一个引用位 reference bit(0/1)
- 当需要发生替换时,对于每个被遍历到的页表项:
- 如果引用位为1,则设置为0并检查下一个页面
- 每次替换都从上次结束的位置继续
- 如果引用位为0,则进行替换并初始化引用位为1
- 如果引用位为1,则设置为0并检查下一个页面
The realization of page table structure
Hierarchical Page Tables 多层表
将虚拟地址分成多个部分,每个部分都有一个表。
- windows
- eg. 2-level paging table -> forward-mapped page table
- 10-bit page num*2 + 12-bit offset
Hashed Page Tables 哈希页表
- 虚拟页号在虚拟地址中被哈希到哈希表中。
- FreeBSD, Solaris
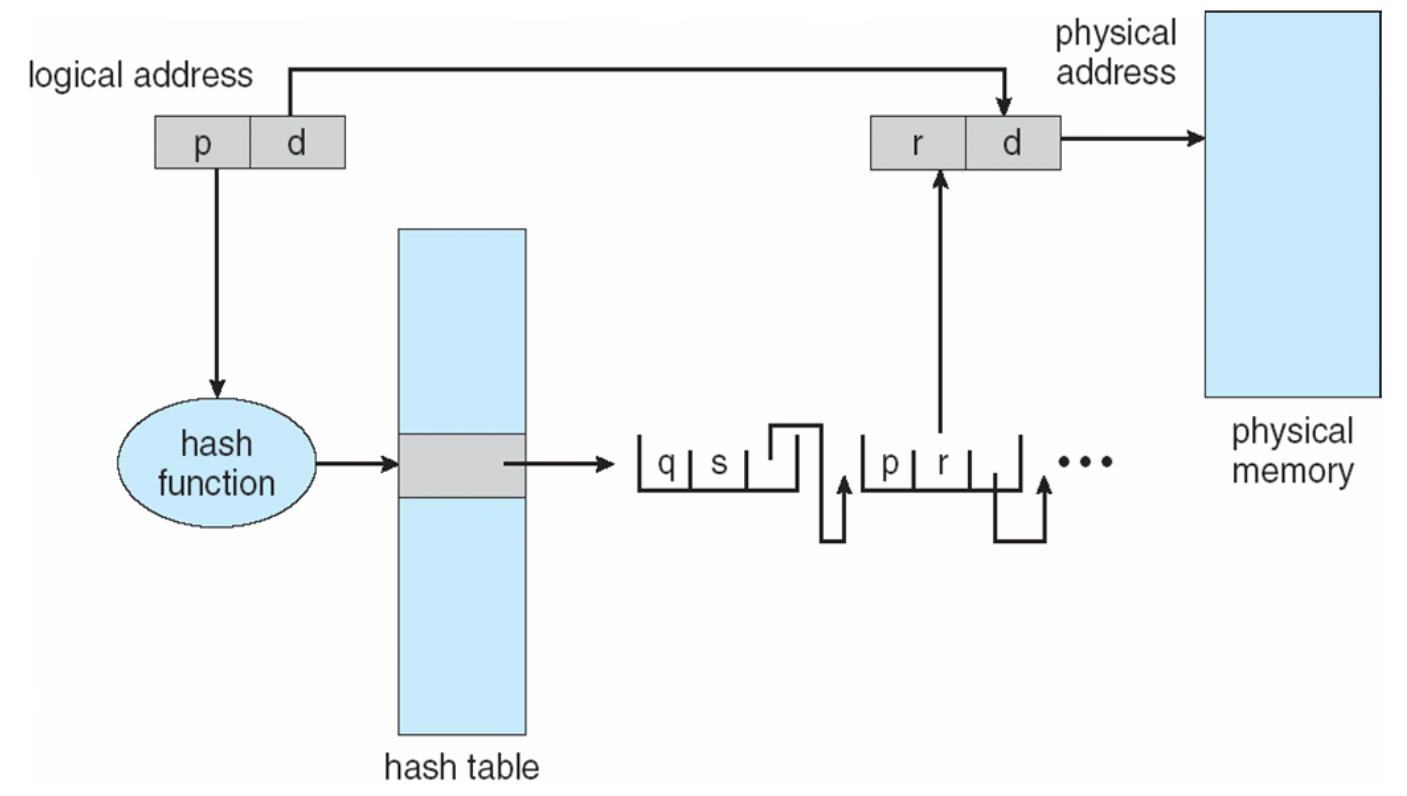
Inverted Page Tables 全局页表
- 由操作系统维护,用于所有进程的页表。
- 条目数等于主存中的帧数。
- 与传统的页表相比具有更小的内存占用(比较直接),但查找时间更长。
- Linux
Segmentation 内存分段
Memory-management scheme that supports user view of memory
可以认为段是一种大小不固定的“页”
Logical address defined as
- ( in paging scheme, we use
- ( in paging scheme, we use
Segment table 分段表
- maps two-dimensional physical addresses
each table entry has
- base
- contains the starting physical address where the segments reside in memory
- limit
- specifies the length of the segment
- base
Simularly keeping the Segment-Table
- Segment-table base register (STBR)
- segment table’s location in memory
- Segment-table length register (STLR)
- indicates number of segments
- used by a program:
- segment number s is legal if s < STLR
- Segment-table base register (STBR)
Segmentation and paging scheme
- Windows
大容量存储系统
Disk 基础
HDD
- Overview
- Drives rotate at 60 to 250 times per second
- Transfer rate is rate at which data flows between drive and computer
- Positioning time (random-access time) is time to move disk arm to desired cylinder (seek time) and time for desired sector to rotate under the disk head (rotational latency)
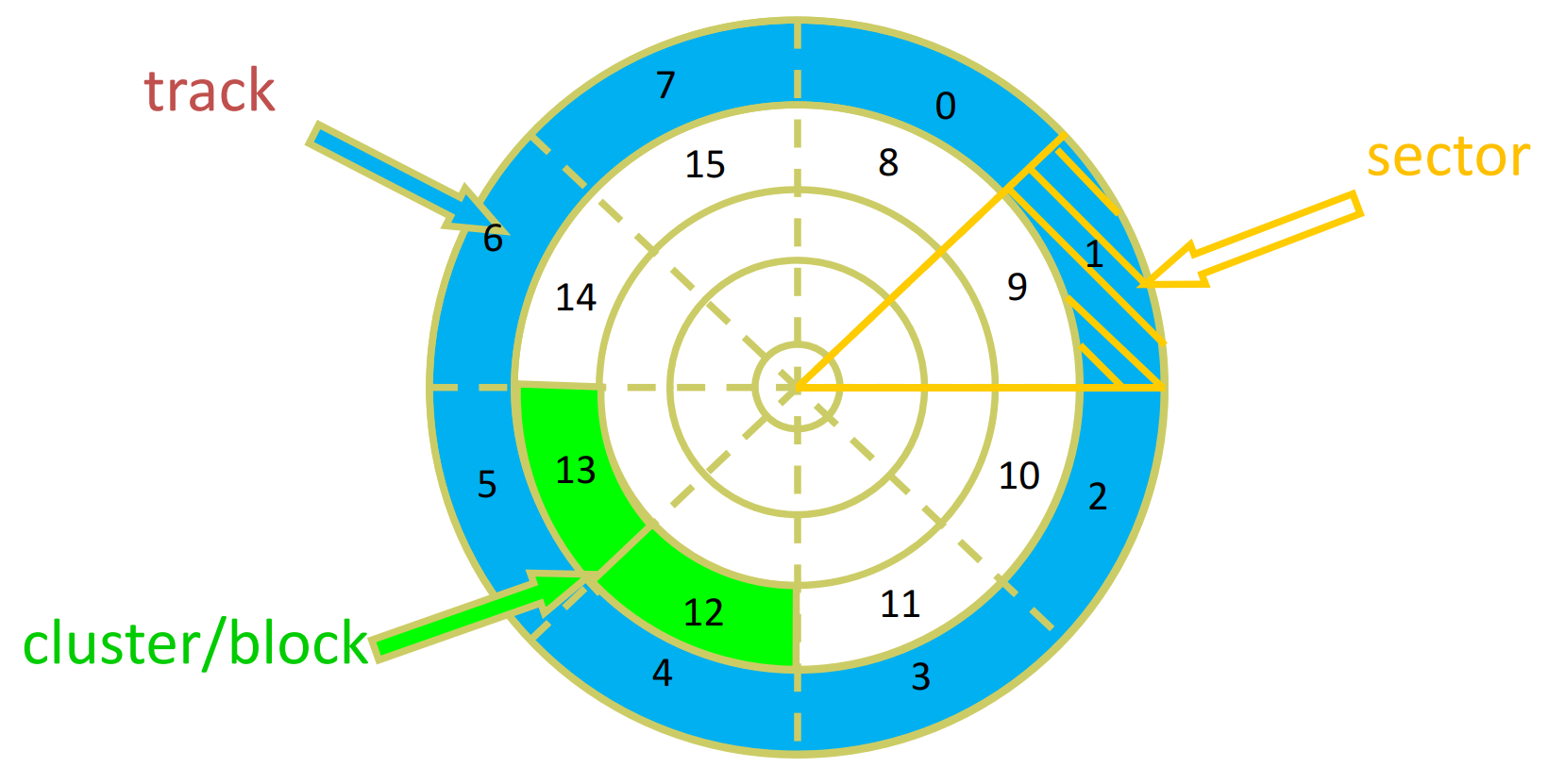
柱面 (cylinder) & 磁道(track)
- 一个盘片的同心圆轨道称为track,所有盘片上的Track组成的一个柱面状的物理结构程伟cylinder
- 在同一Cylinder上的所有track可以同时被磁头访问
- 按cylinder编号不按track编号
- (SSD不存在这两个概念)
扇区 (sector)
- 一个盘片的同心圆轨道内的一个扇形区域
- 扇区0是第一个磁道的第一块扇区
- 每个track的扇区数不固定,与磁盘设计时的角速度有关
簇(cluster):
- 一组相邻的扇区的集合
- 文件系统中的最小单位
- 块(block):
- 由多个扇区组成
- 文件系统管理磁盘空间的基本单位(读写数据的基本单位)。
- 逻辑地址的编码
- large 1-d arrays of logical blocks (smallest unit)
- is mapped into the sectors of the disk sequentially
- Mapping proceeds in order through that track, then the rest of the tracks in that cylinder, and then through the rest of the cylinders from outermost to innermost
- Difficulty in mapping from logical to physical address
- Except for bad sectors
- 操作系统检查坏块并在编码时排除
SSD
- 页(page):页是SSD中最小的可读写单元,通常为4KB或8KB大小。
- 块(block):类似HHD。由多个页构成。为了增大擦除时一次性操作的块的大小延长寿命,在SSD中通常更大,通常为128KB或256KB大小。(理由后面细说)
Disk-Scheduling Algorithms
Idle disk can immediately work on I/O request
Busy disk means work must be queued
(Optimization algorithms only make sense when a queue exists)
FCFS
按queue处理
SSTF
Shortest Seek Time First selects the request with the minimum seek time from the current head position (当前最近)
SCAN
The disk arm starts at one end of the disk, and moves toward the other end,
servicing requests until it gets to the other end of the disk, where the head
movement is reversed and service continues.
C-SCAN
The head moves from one end of the disk to the other, servicing requests as it goes. When it reaches the other end, it immediately returns to the beginning of the disk, without servicing any requests on the return trip.
C-LOOK
Similar to C-SCAN, but doesn’t reach the two ends.
Arm only goes as far as the last request in each direction, then reverses direction immediately, without first going all the way to the end of the disk
-》 in C-XXXX , arm services always occur in one direction. when they are moving are the opposite direction, they ‘immediately returns‘.
SSD vs HDD
Nonvolatile memory devices
- disk-drive like -> solid-state disks (SSD)
- (Other forms include USB drives (thumb drive, flash drive), DRAM stick, and main storage in devices like smartphones )
- Storage capacity / price
capacity: HDD usually > SSD
price : SDD usually > HDD (per MB)magnetic disks (HDD) hold much more data. - Reliability
- SSD > HDD
- SSDs have no moving parts (like magnetic disks and read/write heads) ->less possible to damage
- SSD > HDD
- ==Lifespan==
- SSD << HDD
- -> SSD need to be carefully managed (storage units have a certain erasing and writing life) -> disk management
- LET’S TALK ABOUT IT LATER
- Speed
- SSD >> HDD
- No moving parts, so no seek time or rotational latency
- Bus speed
- SSD requires a direct connection to a high-speed bus (such as PCI) for maximum performance
- (while HDDs are not subject to this limitation)
- ==Disk management==
- SSDs need to implement complex flash controller algorithms, such as garbage collection, wear leveling, etc., to manage storage space.
- HDDs, on the other hand, require low-level formatting (physical formatting) and logical formatting (logical formatting) to create file systems and deal with problems such as bad blocks.
- LET’S TALK ABOUT IT LATER
- ==Space management==
- In HDD, the file system usually uses clusters (簇) to manage disk space, and the size of the cluster is usually fixed.
- In SSD, due to the complexity of its internal data management method, the file system usually needs to adopt different space management strategies, such as TRIM command and garbage collection (Garbage Collection), etc., to maintain the performance and lifespan of SSD.
- LET’S TALK ABOUT IT LATER
Space & Disk Management
HDD
- -> Dividing a disk into sectors that the disk controller can read and write
- Each sector can hold header information + data + error correction code (ECC)
- Usually 512b data but can be selectable
- OS needs to record its own data structures on the disk
- Part groups of cylinders, each treated as a logical disk
- Logical formatting or “making a file system”
- To increase efficiency most file systems group blocks into clusters
Disk I/O done in blocks ; File I/O done in clusters
- Boot block initializes system
- The bootstrap is stored in ROM
- Bootstrap loader program stored in boot blocks of boot partition
- Methods such as sector sparing used to handle bad blocks
MBR
- Boot code + partition table (contains pointer to boot partition)
SSD
- Read and written in “page” increments (think sector)
- ==but can’t overwrite in place==
- Must first be erased, and erases happen in larger “block” increments
- 要修改或擦除一个页,需要先将整个块读取到内存中,然后进行修改或擦除,最后再将整个块写回SSD。(所以SSD的块常常比HHD大的多,以增大每次擦写的大小、减小擦写次数)
- Can only be erased a limited number of times before worn out ~ 100,000
- Life span measured in drive writes per day (DWPD)
- A 1TB NAND drive with rating of 5DWPD is expected to have 5TB per day written within warrantee period without failing
- 块级别的操作对于SSD的性能和寿命管理是非常重要的。-》
- ==but can’t overwrite in place==
NAND Flash Controller Algorithms
- With no overwrite, pages end up with mix of valid and invalid data. We need ways to manage them:
- flash translation layer (FTL) table (a part of NAND flash)
- Track which logical blocks are valid
- TRIM (a instruction involving SSD and OS)
- inform which logical blocks are invalid more flexibly and timely
- Garbage collection (GC)
- Allocates overprovisioning to provide working space for GC
- 垃圾回收是SSD内部的一种自动化操作,用于清理和整理闲置和无效的页。当文件被删除或修改时,SSD的页可能会变得闲置或无效,但这些页实际上仍然占据着宝贵的存储空间。垃圾回收操作会定期或在需要时将这些闲置和无效的页整理到一起,并执行擦除操作,以便可以重新分配给新的数据,从而提高SSD的存储效率。
- flash translation layer (FTL) table (a part of NAND flash)
- Write Wear Leveling (均衡写入耗损)
- Each cell has lifespan, try to write equally to all cells
- 这可以通过在写入新数据时选择尽可能少使用写入次数较多的块,或将写入数据随机分布到多个块中来实现。
Disk Attachment
- Drive attached to computer via I/O bus
- Host controller in computer uses bus to talk to disk controller built into drive
- Busses vary (protocols vary)
- 接口协议规定了硬件设备之间的通信协议和通信方式,而数据总线BUS则是物理连接这些设备之间的通信通道。
- including EIDE, ATA, SATA, USB, SCSI, Fiber Channel, SAS, Firewire…
- 家用计算机的CPU多使用PCI、SATA等接口协议,FC更多用于企业计算机和数据中心环境。
- SCSI(Small Computer System Interface)
- 过去比较常见
- a bus, up to 16 devices on one cable
- SCSI initiator 发起器 requests operation 发送操作请求 and SCSI targets 目标设备 perform tasks
- Each target can have up to 8 logical units (disks attached to device controller)
- FC (Fiber Channel) 光纤通道
- a high-speed serial architecture
- Can be switched fabric with 24-bit address space – the basis of storage area networks (SANs 存储区域网络) in which many hosts attach to many storage units
- 通常用于需要大规模存储和高速数据传输的应用场景
RAID
- Redundant Arrays of Independent Disks (RAIDs)
- RAID– multiple disk drives provides reliability via redundancy
- Mirroring ( -> a second copy)
- duplicate every disk
- Parity bit ( -> error-correcting bit)
- Mirroring ( -> a second copy)
- Parallel access to multiple disk improves performance
- Bit-level striping
- split the bits of each byte across multiple disks
- block-level striping
- blocks of a file are striped across multiple disks
- Bit-level striping
- RAID is arranged into seven or more different levels
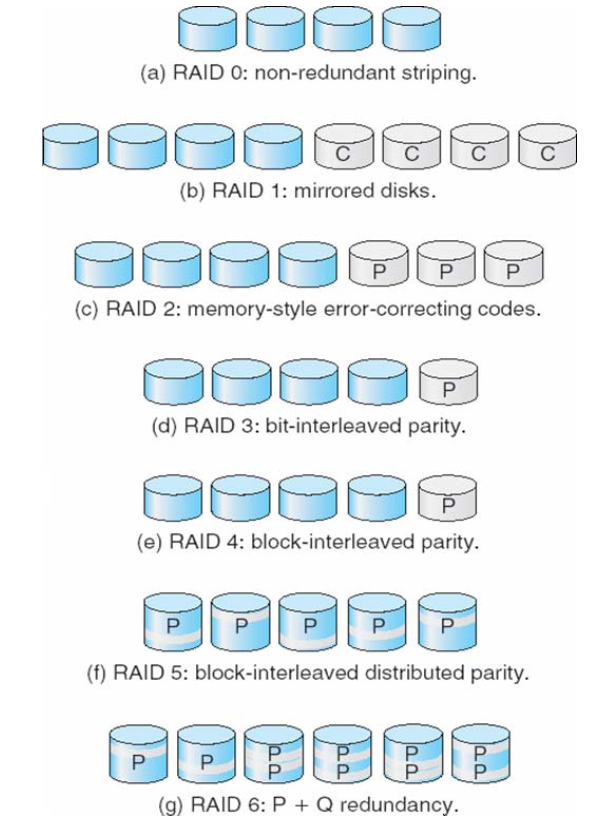
RAID 6: P + Q redundancy
- Reed-Solomon codes
- 2 bits of redundant data are stored for every 4 bits of data
- 在RAID6中,数据被分布式地存储在多个磁盘驱动器中,同时通过计算奇偶校验信息对数据进行冗余存储。RAID6采用两个奇偶校验盘(P和Q盘)来存储奇偶校验信息,从而实现了对两个磁盘驱动器的故障容忍。
交织分布奇偶校验(如RAID 5)和复制(如RAID 1)是两种不同的数据保护策略,它们在数据存储和容错方式上有以下区别:
假设有一个包含4个数据盘和1个奇偶校验盘的RAID 5阵列,其中数据盘分别标记为D1、D2、D3、D4,奇偶校验盘标记为P。当一个数据盘出现故障时,可以通过从其他数据盘和奇偶校验盘中恢复数据。
例如,当D2数据盘出现故障时,需要从其他数据盘和奇偶校验盘中恢复D2上的数据。RAID 5使用异或(XOR)运算来生成奇偶校验信息,该运算具有可逆性,可以用于数据恢复。
假设D1、D3和D4上的数据分别为A、B和C,而P上的奇偶校验信息为A XOR B XOR C。现在需要恢复D2上的数据B,可以通过执行以下步骤:
- 从D1、D3和D4中读取对应位置上的数据,得到A、B和C的值。
- 从奇偶校验盘P中读取对应位置上的奇偶校验信息,得到A XOR B XOR C的值。
- 通过对已知的A、B和C的值以及A XOR B XOR C的值执行异或运算,即 (A XOR B XOR C) XOR (A XOR C) = B,得到D2上的数据B的值。
- 将得到的B的值写入到替换后的新数据盘D2上,完成数据恢复。
这样,通过从其他数据盘和奇偶校验盘中恢复数据,可以在某个数据盘出现故障时保护数据的完整性,并维持RAID 5阵列的可靠性和可用性。
Network-Attached Storage
- Network-attached storage (NAS) is storage made available over a network rather than over a local connection (such as a bus)
- Remotely attaching to file systems
- Implemented via remote procedure calls (RPCs) between host and storage over typically TCP or UDP on IP network
- iSCSI protocol uses IP network to carry the SCSI protocol
- Remotely attaching to devices (blocks) -> virtual disks
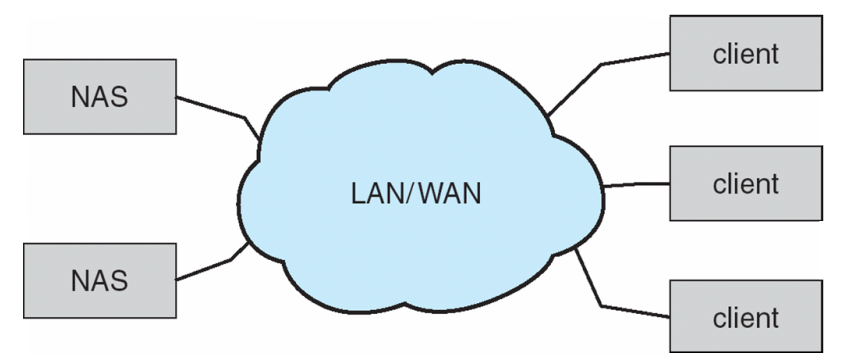
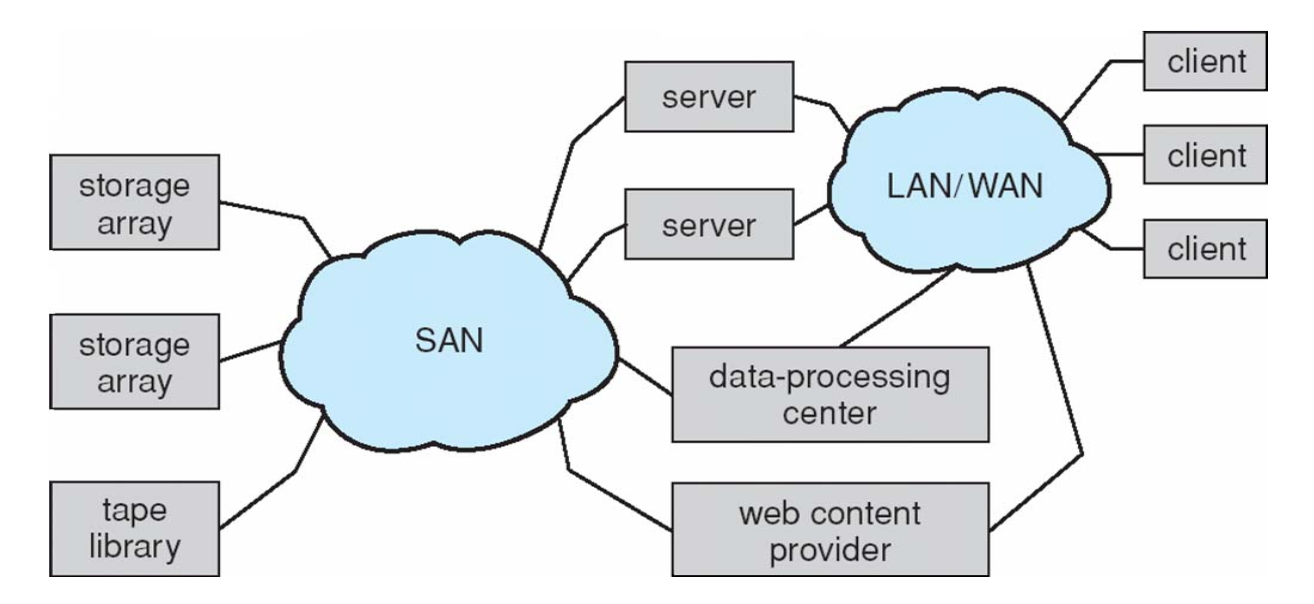
- Storage Area Network(SAN)存储区域网络
- Common in large storage environments
- Multiple hosts attached to multiple storage arrays - flexible
- use high-speed buses,like Fibre Channel or iSCSI