现代操作系统CS2310 (附)虚拟机和分布式
虚拟机
Overview
- Fundamental idea
- abstract hardware of a single computer into several different execution environments
- Similar to layered approach
- But layer creates virtual system (virtual machine, or VM) on which operation systems or applications can run
- Several components
- Host 宿主机
- underlying hardware system where VM runs
- Virtual machine manager (VMM) 虚拟机管理器 / hypervisor (hyper-V) 虚拟化监控程序
- creates and runs virtual machines by providing interface that is identical to the host
- (except in the case of paravirtualization 部分虚拟化)
- Guest 客户机
- process provided with virtual copy 虚拟副本 of the host
- usually an operating system
- Host 宿主机
- Single physical machine can run multiple operating systems concurrently 同时, each in its own virtual machine


分布式系统 Distributed System
分布式系统结构
Motivation 动机
在分布式系统中,多个计算机节点(node)协同工作以完成某项任务。这种方式比单个计算机处理大规模问题更高效。因此,分布式系统在大规模计算和数据处理方面有着广泛的应用。
- 分布式系统是由松散耦合的处理器通过通信网络相互连接而成的集合。
- 处理器
- 也称为节点/计算机/机器/主机等
- 站点 Site 指处理器的位置
好处
- 资源共享 Resource sharing
- 在远程站点共享和打印文件
- 在分布式数据库中处理信息
- 使用远程专用硬件设备
- 计算速度提升 Computation speedup
- 负载均衡 load sharing
- 可靠性
- 检测和从站点故障中恢复,功能转移,重新整合失败的站点
- 通信
- 消息传递
- 资源共享 Resource sharing
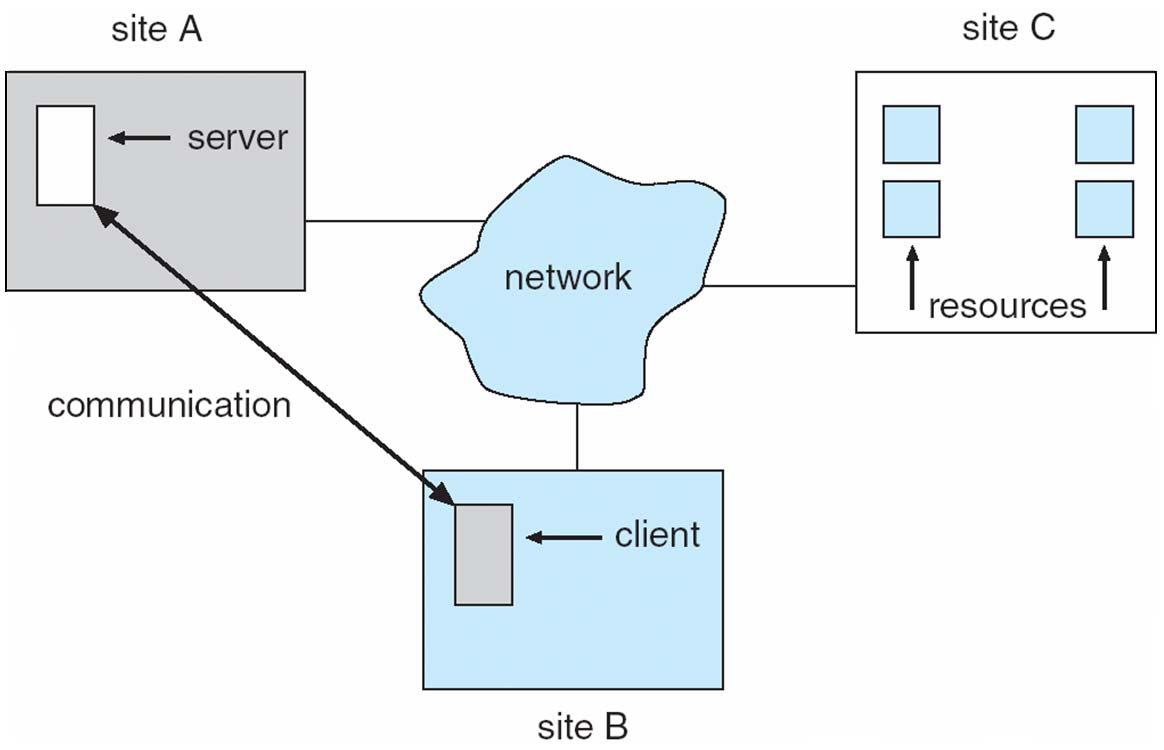
Example
中心的格子代表整个网络,表示分布式系统的总体框架
- 三类站点接入网络
- Site A “server”
- 站点上有一个服务器
- 它可以为其他站点提供服务
- Site B “client”
- 站点上有一个客户端
- 它可以向服务器请求服务
- Site A 和 Site B 可以互相通信。
- Site C “resources”
- 有一些资源,如硬件设备、数据库等
- Site C 与其他站点没有直接的连接,但可以通过网络来访问其中的资源
- Site A “server”
网络操作系统 vs 分布式操作系统
网络操作系统主要是为了方便用户在多个计算机之间进行远程访问和操作,而分布式操作系统则是整合了多个计算机的系统资源,让它们像一个系统一样工作,能够实现负载均衡、资源共享、容错等功能。两者的目标和实现方式都有很大的差异。
网络操作系统
- 用户知道有多个计算机。显式地访问不同计算机的资源,可以通过以下方式实现:
- 远程登录到适当的远程计算机(telnet、ssh)
- 远程桌面(Microsoft Windows)
- 通过文件传输协议(FTP)机制从远程计算机传输数据到本地计算机
分布式操作系统
- 用户不知道有多个计算机
- 访问远程资源类似于访问本地资源
- 数据迁移
- 通过传输整个文件或仅传输立即任务所需的文件部分来传输数据
- 计算迁移
- 在系统中传输计算而不是数据
- 进程迁移
- 在不同站点执行整个进程或进程的部分
- 负载平衡
- 在网络中分配进程以平衡工作负载
- 计算加速
- 子进程可以在不同站点同时运行
- 硬件优先
- 进程执行可能需要专门的处理器
- 软件优先
- 所需软件可能仅在特定站点可用
- 数据访问
- 在不同站点运行进程时,访问相应数据的方法可能不同
Network Structure 网络结构
(从这里开始全是计算机网络的课程内容……不愧是你SJTU(。。。))
本地区域网络 Local-Area Network(LAN)
- 设计用于覆盖小范围地理区域。
- 多路访问总线、环形或星形网络
- 速度约为10-100兆比特/秒,甚至千兆比特/秒
- 广播快速且便宜
- 节点
- 通常是工作站和/或个人计算机
- 几个(通常是一个或两个)大型机
广域网 Wide-Area Network( WAN)
- 链接地理上分离的站点
- 通过远距离线路进行点对点连接(通常是从电话公司租用)
- 速度约为1.544-45兆比特/秒
- 广播通常需要多个消息
- 节点
- 通常有高比例的大型机 mainframes
网络拓扑 Network Topology
网络拓扑结构
- 系统中的站点可以以多种方式进行物理连接,可以根据以下标准进行比较:
- 安装成本 - 将系统中的各个站点连接起来的成本有多高?
- 通信成本 - 从站点A发送消息到站点B需要多长时间?
- 可靠性 - 如果系统中的链接或站点发生故障,是否仍然可以相互通信?
- 不同的拓扑结构可用图形表示,其节点对应于站点
- 从节点A到节点B的边缘对应于两个站点之间的直接连接
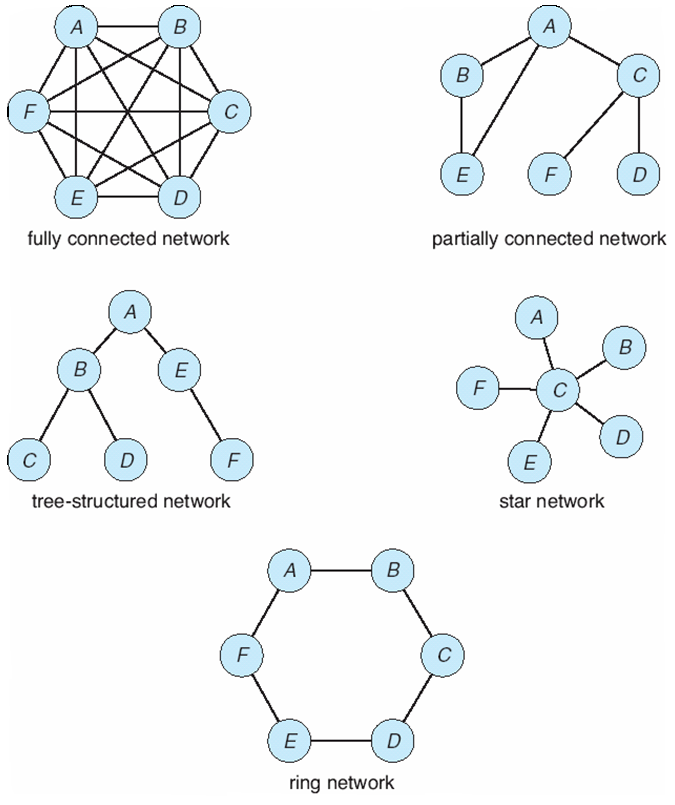
分布式系统需要一个底层的网络基础架构来支持节点间的通信。网络结构包括网络硬件和软件组件。
Network Topology(网络拓扑) 网络拓扑指的是计算机网络中连接节点的方式。常见的网络拓扑包括总线、环、星型、树形、网状等。
Communication Structure(通信结构) 通信结构是指节点间数据传输的方式。常见的通信结构包括客户端-服务器结构、对等结构、多播结构等。
Communication Protocols(通信协议) 通信协议是指节点间通信所遵循的规则。常见的通信协议包括TCP/IP协议、HTTP协议、FTP协议等。
Robustness(健壮性) 分布式系统需要具备健壮性,即在节点故障、网络故障等不可避免的情况下能够继续运行。为实现健壮性,分布式系统需要具备一些特性,例如冗余、容错性等。
Design Issues(设计问题) 设计分布式系统时需要考虑一些问题,例如数据一致性、同步、并发等。
An Example: Networking(案例:网络) 网络是一个典型的分布式系统,它由多个节点组成,并通过网络协议实现节点间通信。网络的设计需要考虑节点的安全性、带宽管理等问题。
分布式文件系统
基础
DFS 的结构是由服务、服务器和客户端三个组成部分构成的,其中客户端接口应该是透明的,使得用户可以像访问本地文件一样访问远程文件,提高了文件共享和管理的效率。
- Service
运行在一个或多个计算机上的软件实体,向预先未知的客户端提供特定类型的功能。 - Server
运行在单个计算机上的服务软件,负责提供服务。 - Client
可以使用一组操作调用服务的进程,形成客户端接口 Client interface。对于文件服务的客户端接口由一组原始文件操作(创建、删除、读取、写入等)组成。 - DFS 的客户端接口应该是透明 transparent的,即不应区分本地文件和远程文件。
- 指用户可以像访问本地文件一样访问远程文件,而不必关心文件实际存储在在哪个服务器、哪个位置。
- 通过透明的 DFS,用户可以访问整个分布式系统中的文件,而不必关心它们存储在哪里。
DFS 通常由多个服务器组成,这些服务器分别处理文件存储和管理、数据备份、安全性、性能等方面的任务。
此外,DFS 还支持数据冗余和备份,以提高系统的可靠性和容错性。
命名 Naming
定义:逻辑对象与物理对象之间的映射关系 mapping
-> 多级映射 Multilevel mapping
- 对文件的抽象隐藏了文件实际存储在磁盘上的细节
- 因此需要实现:
- 从名称到标识符Name to identifier,
- 从标识符到块和位置 Identifier to blocks and locations (inode)
的映射
- 对于一个文件存在多个副本的情况,映射将变得更加复杂
- 对于在多个站点复制的文件,映射会返回该文件副本的位置集合,多个副本的存在以及它们的位置都是被隐藏的。
命名结构
目标
- 位置透明性 Location transparency
- 文件名不揭示文件的物理存储位置
- (用户不需要知道文件存储在哪个服务器上,就能通过文件名来访问该文件)
- 文件名不揭示文件的物理存储位置
- 位置独立性 Location independence
- 文件名不需要在文件的物理存储位置发生变化时进行更改
- (用户在访问文件时,不受文件实际存储位置的影响)
- 文件名不需要在文件的物理存储位置发生变化时进行更改
命名方法
<主机名,本地名>
- 保证了唯一的系统范围内名称
- 不支持位置独立性&位置透明性。
目录树 directory tree
- 将远程目录附加到本地目录构成连贯的目录树
- 只有已经挂载的远程目录可以被透明地访问
- UNIX
组件文件系统的完全集成 total integration of the component file systems
- 一个全局名称结构跨越系统中的所有文件
- 如果某个服务器不可用,某些不同机器上的目录也会变得不可用
- 比较复杂,支持位置独立性和位置透明性
- AFS
远程文件访问与缓存
Remote File Access & Cache
- 可以通过远程过程调用(RPC)支持远程文件访问
- 缓存
- 在缓存中保留最近访问的磁盘块处理重复访问相同信息
- 如果需要的数据不在缓存中,从服务器端获取一份数据的副本,然后在缓存副本上执行访问操作
- 文件有一个主副本存储在服务器上,但文件的(部分)副本分散在不同的缓存中
- 缓存一致性问题 Cache-consistency problem
- 保持缓存副本与主文件的一致性
-> 这种远程文件访问机制有时也被称为网络虚拟内存
- 保持缓存副本与主文件的一致性
- 在缓存中保留最近访问的磁盘块处理重复访问相同信息
- 使用磁盘/主存进行缓存?
- 磁盘
- 可靠
- 恢复期间,缓存的数据仍保留在磁盘上,无需再次获取
- 主存
- 允许工作站无磁盘,节省成本
- 数据访问更快
- 更大的内存可以提高性能
- 服务器缓存通常在主存中,不管用户缓存的位置在哪里,使用主存缓存可以为服务器和用户提供单一的缓存机制
- 磁盘
缓存更新策略 Cache Update Policy
写穿(Write-through)
- 将数据放置在任何缓存中后立即通过到磁盘上
- 可靠性高,但性能差
延迟写(Delayed-write 或 Write Back)
- 修改写入缓存,稍后再写入服务器
- 写入操作快速完成,但有些数据可能在写回之前被覆盖,因此根本不需要写回
- 可靠性差;未写入的数据将在用户机器崩溃时丢失
- 变体1:定期扫描缓存,并刷新自上次扫描以来已被修改的块
- 变体2:在关闭文件时写回,将数据写回服务器
- 对于长时间打开且经常修改的文件最佳
- AFS
一致性 Consistency
本地缓存的数据是否与主副本一致?
客户端主动检查 Client-initiated approach
- 客户端启动有效性检查
- 服务器检查本地数据是否与主副本一致
- 有效性检查validity check和访问性能access performance之间进行权衡
服务器主动检查Server-initiated approach
- 服务器为每个客户端记录(部分)它缓存的文件
- 当服务器检测到潜在的不一致时,必须采取措施
缓存和远程服务机制比较
- 缓存机制能够高效地处理许多远程访问,因为本地缓存可以快速响应大多数远程访问,而仅偶尔需要访问服务器。
- 可以减少服务器负载和网络流量。
- 可以提高可扩展性。
- 远程服务机制需要处理每一个远程访问,导致网络流量、服务器负载和性能开销的增加。
- 在缓存中,对于写访问较少的情况下表现更好。
- 频繁写操作会导致解决缓存一致性问题的重大开销。
- 在具有本地磁盘或大容量主存储器的机器上执行时,可以从缓存中受益。
- 对于无磁盘、小内存容量机器上的远程访问,应该使用远程服务方法。
- 在缓存中,较低层的机器接口与上层用户接口不同。
- 在远程服务中,机器接口反映了本地用户文件系统接口。
Stateful File Service 状态文件服务
- 状态服务机制
- 客户端打开一个文件
- 服务器从其磁盘中获取有关文件的信息,将其存储在内存中,并为客户端提供对于客户端和打开文件唯一的连接标识符
- 标识符在之后的访问中使用,直到会话结束
- 服务器必须收回不再活动的客户端使用的主存空间
性能
- 较少的磁盘访问
- 状态服务器知道文件是否以顺序访问的方式打开,因此可以预读下一个块
无状态文件服务器 Stateless File Server
- 通过使每个请求自包含避免状态信息
- 每个请求标识文件和文件位置
- 无需通过打开和关闭操作建立和终止连接
区别
失败恢复
- 有状态的服务器在崩溃时会失去所有易失性状态
- 通过基于与客户端对话的恢复协议恢复状态,或中止崩溃发生时正在进行的操作
- 服务器需要知道客户端故障,以便回收为记录崩溃客户端进程状态而分配的空间(孤儿检测和消除)
- 使用无状态服务器,服务器失败和恢复的影响几乎是不可察觉的
- 新的重生服务器可以回答自包含请求而无需任何困难
- 有状态的服务器在崩溃时会失去所有易失性状态
使用健壮的无状态服务的惩罚
- 较长的请求消息
- 较慢的请求处理
- 对 DFS 设计施加额外的限制
某些环境需要状态服务
- 使用服务器发起的缓存验证的服务器无法提供无状态服务,因为它维护记录哪个客户端缓存了哪个文件的记录
- UNIX 使用文件描述符和隐式偏移是固有的有状态的;服务器必须维护映射文件描述符到 inode 的表,并存储文件中的当前偏移量
文件复制 File Replication
- 同一文件的副本存储在相互独立的机器上
- 提高可用性并缩短服务时间
- 命名方案
- 将复制文件名映射到特定副本
- 复制的存在对上层不可见
- 副本必须通过不同的低级名称互相区分
- 但有时候为了性能目的,文件复制机制对用户是可见的,如Lucas
- 更新
- 文件的副本表示同一逻辑实体
- 对任何副本的更新必须反映在所有其他副本上
- 需求复制 Demand replication
- 读取非本地副本会导致它在本地缓存,从而生成新的非主副本